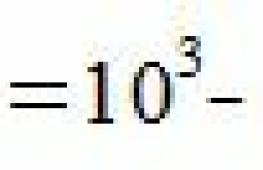Дисперсия может быть рассчитана для признака. Дисперсия
Шаги
Вычисление дисперсии выборки
-
Запишите значения выборки. В большинстве случаев статистикам доступны только выборки определенных генеральных совокупностей. Например, как правило, статистики не анализируют расходы на содержание совокупности всех автомобилей в России – они анализируют случайную выборку из нескольких тысяч автомобилей. Такая выборка поможет определить средние расходы на автомобиль, но, скорее всего, полученное значение будет далеко от реального.
- Например, проанализируем количество булочек, проданных в кафе за 6 дней, взятых в случайном порядке. Выборка имеет следующий вид: 17, 15, 23, 7, 9, 13. Это выборка, а не совокупность, потому что у нас нет данных о проданных булочках за каждый день работы кафе.
- Если вам дана совокупность, а не выборка значений, перейдите к следующему разделу.
-
Запишите формулу для вычисления дисперсии выборки. Дисперсия является мерой разброса значений некоторой величины. Чем ближе значение дисперсии к нулю, тем ближе значения сгруппированы друг к другу. Работая с выборкой значений, используйте следующую формулу для вычисления дисперсии:
- s 2 {\displaystyle s^{2}} = ∑[( x i {\displaystyle x_{i}} - x̅) 2 {\displaystyle ^{2}} ] / (n - 1)
- s 2 {\displaystyle s^{2}} – это дисперсия. Дисперсия измеряется в квадратных единицах измерения.
- x i {\displaystyle x_{i}} – каждое значение в выборке.
- x i {\displaystyle x_{i}} нужно вычесть x̅, возвести в квадрат, а затем сложить полученные результаты.
- x̅ – выборочное среднее (среднее значение выборки).
- n – количество значений в выборке.
-
Вычислите среднее значение выборки. Оно обозначается как x̅. Среднее значение выборки вычисляется как обычное среднее арифметическое: сложите все значения в выборке, а затем полученный результат разделите на количество значений в выборке.
- В нашем примере сложите значения в выборке: 15 + 17 + 23 + 7 + 9 + 13 = 84
Теперь результат разделите на количество значений в выборке (в нашем примере их 6): 84 ÷ 6 = 14.
Выборочное среднее x̅ = 14. - Выборочное среднее – это центральное значение, вокруг которого распределены значения в выборке. Если значения в выборке группируются вокруг выборочного среднего, то дисперсия мала; в противном случае дисперсия велика.
- В нашем примере сложите значения в выборке: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
Вычтите выборочное среднее из каждого значения в выборке. Теперь вычислите разность x i {\displaystyle x_{i}} - x̅, где x i {\displaystyle x_{i}} – каждое значение в выборке. Каждый полученный результат свидетельствует о мере отклонения конкретного значения от выборочного среднего, то есть как далеко это значение находится от среднего значения выборки.
- В нашем примере:
x 1 {\displaystyle x_{1}} - x̅ = 17 - 14 = 3
x 2 {\displaystyle x_{2}} - x̅ = 15 - 14 = 1
x 3 {\displaystyle x_{3}} - x̅ = 23 - 14 = 9
x 4 {\displaystyle x_{4}} - x̅ = 7 - 14 = -7
x 5 {\displaystyle x_{5}} - x̅ = 9 - 14 = -5
x 6 {\displaystyle x_{6}} - x̅ = 13 - 14 = -1 - Правильность полученных результатов легко проверить, так как их сумма должна равняться нулю. Это связано с определением среднего значения, так как отрицательные значения (расстояния от среднего значения до меньших значений) полностью компенсируются положительными значениями (расстояниями от среднего значения до больших значений).
- В нашем примере:
-
Как отмечалось выше, сумма разностей x i {\displaystyle x_{i}} - x̅ должна быть равна нулю. Это означает, что средняя дисперсия всегда равна нулю, что не дает никакого представления о разбросе значений некоторой величины. Для решения этой проблемы возведите в квадрат каждую разность x i {\displaystyle x_{i}} - x̅. Это приведет к тому, что вы получите только положительные числа, которые при сложении никогда не дадут 0.
- В нашем примере:
( x 1 {\displaystyle x_{1}} - x̅) 2 = 3 2 = 9 {\displaystyle ^{2}=3^{2}=9}
(x 2 {\displaystyle (x_{2}} - x̅) 2 = 1 2 = 1 {\displaystyle ^{2}=1^{2}=1}
9 2 = 81
(-7) 2 = 49
(-5) 2 = 25
(-1) 2 = 1 - Вы нашли квадрат разности - x̅) 2 {\displaystyle ^{2}} для каждого значения в выборке.
- В нашем примере:
-
Вычислите сумму квадратов разностей. То есть найдите ту часть формулы, которая записывается так: ∑[( x i {\displaystyle x_{i}} - x̅) 2 {\displaystyle ^{2}} ]. Здесь знак Σ означает сумму квадратов разностей для каждого значения x i {\displaystyle x_{i}} в выборке. Вы уже нашли квадраты разностей (x i {\displaystyle (x_{i}} - x̅) 2 {\displaystyle ^{2}} для каждого значения x i {\displaystyle x_{i}} в выборке; теперь просто сложите эти квадраты.
- В нашем примере: 9 + 1 + 81 + 49 + 25 + 1 = 166 .
-
Полученный результат разделите на n - 1, где n – количество значений в выборке. Некоторое время назад для вычисления дисперсии выборки статистики делили результат просто на n; в этом случае вы получите среднее значение квадрата дисперсии, которое идеально подходит для описания дисперсии данной выборки. Но помните, что любая выборка – это лишь небольшая часть генеральной совокупности значений. Если взять другую выборку и выполнить такие же вычисления, вы получите другой результат. Как выяснилось, деление на n - 1 (а не просто на n) дает более точную оценку дисперсии генеральной совокупности, в чем вы и заинтересованы. Деление на n – 1 стало общепринятым, поэтому оно включено в формулу для вычисления дисперсии выборки.
- В нашем примере выборка включает 6 значений, то есть n = 6.
Дисперсия выборки = s 2 = 166 6 − 1 = {\displaystyle s^{2}={\frac {166}{6-1}}=} 33,2
- В нашем примере выборка включает 6 значений, то есть n = 6.
-
Отличие дисперсии от стандартного отклонения. Заметьте, что в формуле присутствует показатель степени, поэтому дисперсия измеряется в квадратных единицах измерения анализируемой величины. Иногда такой величиной довольно сложно оперировать; в таких случаях пользуются стандартным отклонением, которое равно квадратному корню из дисперсии. Именно поэтому дисперсия выборки обозначается как s 2 {\displaystyle s^{2}} , а стандартное отклонение выборки – как s {\displaystyle s} .
- В нашем примере стандартное отклонение выборки: s = √33,2 = 5,76.
Вычисление дисперсии совокупности
-
Проанализируйте некоторую совокупность значений. Совокупность включает в себя все значения рассматриваемой величины. Например, если вы изучаете возраст жителей Ленинградской области, то совокупность включает возраст всех жителей этой области. В случае работы с совокупностью рекомендуется создать таблицу и внести в нее значения совокупности. Рассмотрим следующий пример:
- В некоторой комнате находятся 6 аквариумов. В каждом аквариуме обитает следующее количество рыб:
x 1 = 5 {\displaystyle x_{1}=5}
x 2 = 5 {\displaystyle x_{2}=5}
x 3 = 8 {\displaystyle x_{3}=8}
x 4 = 12 {\displaystyle x_{4}=12}
x 5 = 15 {\displaystyle x_{5}=15}
x 6 = 18 {\displaystyle x_{6}=18}
- В некоторой комнате находятся 6 аквариумов. В каждом аквариуме обитает следующее количество рыб:
-
Запишите формулу для вычисления дисперсии генеральной совокупности. Так как в совокупность входят все значения некоторой величины, то приведенная ниже формула позволяет получить точное значение дисперсии совокупности. Для того чтобы отличить дисперсию совокупности от дисперсии выборки (значение которой является лишь оценочным), статистики используют различные переменные:
- σ 2 {\displaystyle ^{2}} = (∑( x i {\displaystyle x_{i}} - μ) 2 {\displaystyle ^{2}} ) / n
- σ 2 {\displaystyle ^{2}} – дисперсия совокупности (читается как «сигма в квадрате»). Дисперсия измеряется в квадратных единицах измерения.
- x i {\displaystyle x_{i}} – каждое значение в совокупности.
- Σ – знак суммы. То есть из каждого значения x i {\displaystyle x_{i}} нужно вычесть μ, возвести в квадрат, а затем сложить полученные результаты.
- μ – среднее значение совокупности.
- n – количество значений в генеральной совокупности.
-
Вычислите среднее значение совокупности. При работе с генеральной совокупностью ее среднее значение обозначается как μ (мю). Среднее значение совокупности вычисляется как обычное среднее арифметическое: сложите все значения в генеральной совокупности, а затем полученный результат разделите на количество значений в генеральной совокупности.
- Имейте в виду, что средние величины не всегда вычисляются как среднее арифметическое.
- В нашем примере среднее значение совокупности: μ = 5 + 5 + 8 + 12 + 15 + 18 6 {\displaystyle {\frac {5+5+8+12+15+18}{6}}} = 10,5
-
Вычтите среднее значение совокупности из каждого значения в генеральной совокупности. Чем ближе значение разности к нулю, тем ближе конкретное значение к среднему значению совокупности. Найдите разность между каждым значением в совокупности и ее средним значением, и вы получите первое представление о распределении значений.
- В нашем примере:
x 1 {\displaystyle x_{1}} - μ = 5 - 10,5 = -5,5
x 2 {\displaystyle x_{2}} - μ = 5 - 10,5 = -5,5
x 3 {\displaystyle x_{3}} - μ = 8 - 10,5 = -2,5
x 4 {\displaystyle x_{4}} - μ = 12 - 10,5 = 1,5
x 5 {\displaystyle x_{5}} - μ = 15 - 10,5 = 4,5
x 6 {\displaystyle x_{6}} - μ = 18 - 10,5 = 7,5
- В нашем примере:
-
Возведите в квадрат каждый полученный результат. Значения разностей будут как положительными, так и отрицательными; если нанести эти значения на числовую прямую, то они будут лежать справа и слева от среднего значения совокупности. Это не годится для вычисления дисперсии, так как положительные и отрицательные числа компенсируют друг друга. Поэтому возведите в квадрат каждую разность, чтобы получить исключительно положительные числа.
- В нашем примере:
( x i {\displaystyle x_{i}} - μ) 2 {\displaystyle ^{2}} для каждого значения совокупности (от i = 1 до i = 6):
(-5,5) 2 {\displaystyle ^{2}} = 30,25
(-5,5) 2 {\displaystyle ^{2}} , где x n {\displaystyle x_{n}} – последнее значение в генеральной совокупности. - Для вычисления среднего значения полученных результатов нужно найти их сумму и разделить ее на n:(( x 1 {\displaystyle x_{1}} - μ) 2 {\displaystyle ^{2}} + ( x 2 {\displaystyle x_{2}} - μ) 2 {\displaystyle ^{2}} + ... + ( x n {\displaystyle x_{n}} - μ) 2 {\displaystyle ^{2}} ) / n
- Теперь запишем приведенное объяснение с использованием переменных: (∑( x i {\displaystyle x_{i}} - μ) 2 {\displaystyle ^{2}} ) / n и получим формулу для вычисления дисперсии совокупности.
- В нашем примере:
Решение.
В качестве меры рассеивания значений случайной величины используется дисперсия
Дисперсия (слово дисперсия означает "рассеяние") есть мера рассеивания значений случайной величины относительно ее математического ожидания. Дисперсией называется математическое ожидание квадрата отклонения случайной величины от ее математического ожидания
Если случайная величина - дискретная с бесконечным, но счетным множеством значений, то
если ряд в правой части равенства сходится.
Свойства дисперсии.
- 1. Дисперсия постоянной величины равна нулю
- 2. Дисперсия суммы случайных величин равна сумме дисперсий
- 3. Постоянный множитель можно выносить за знак дисперсии в квадрате
Дисперсия разности случайных величин равна сумме дисперсий
Это свойство является следствием второго и третьего свойств. Дисперсии могут только складываться.
Дисперсию удобно вычислять по формуле, которую легко получить, используя свойства дисперсии
Дисперсия всегда величина положительная .
Дисперсия имеет размерность квадрата размерности самой случайной величины, что не всегда удобно. Поэтому в качестве показателя рассеяния используют также величину
Средним квадратическим отклонением (стандартным отклонением или стандартом) случайной величиныназывается арифметическое значение корня квадратного из её дисперсии
Бросают две монеты достоинством 2 и 5 рублей. Если монета выпадает гербом, то начисляют ноль очков, а если цифрой, то число очков, равное достоинству монеты. Найти математическое ожидание и дисперсию числа очков.
Решение. Найдем вначале распределение случайной величины Х - числа очков. Все комбинации - (2;5),(2;0),(0;5),(0;0) - равновероятны и закон распределения:

Математическое ожидание:
Дисперсию найдем по формуле
для чего вычислим
Пример 2.
Найти неизвестную вероятность р , математическое ожидание и дисперсию дискретной случайной величины, заданной таблицей распределения вероятностей
Находим математическое ожидание и дисперсию:
M (X ) = 00,0081 + 10,0756 + 20,2646 + 3 0,4116 + +40,2401=2,8
Для вычисления дисперсии воспользуемся формулой (19.4)
D (X ) = 020 ,0081 + 120,0756 + 220,2646 + 320,4116 + 420,2401 - 2,82 = 8,68 -

Пример 3. Два равносильных спортсмена проводят турнир, который длится или до первой победы одного из них, или до тех пор, пока не будет сыграно пять партий. Вероятность победы в одной партии для каждого из спортсменов равна 0,3, а вероятность ничейного исхода партии 0,4. Найти закон распределения, математическое ожидание и дисперсию числа сыгранных партий.
Решение. Случайная величина Х - количество сыгранных партий, принимает значения от 1 до 5, т. е.
Определим вероятности окончания матча. Матч закончится на первой партии, если кто-то их спортсменов выиграл. Вероятность выигрыша равна
Р (1) = 0,3+0,3 =0,6.
Если же была ничья (вероятность ничьей равна 1 - 0,6 = 0,4), то матч продолжается. Матч закончится на второй партии, если в первой была ничья, а во второй кто-то выиграл. Вероятность
Р (2) = 0,4 0,6=0,24.
Аналогично, матч закончится на третьей партии, если было подряд две ничьи и опять кто-то выиграл
Р (3) = 0,4 0,4 0,6 = 0,096. Р (4)= 0,4 0,4 0,4 0,6=0,0384.
Пятая партия в любом варианте последняя.
Р (5)= 1 - (Р (1)+Р (2)+Р (3)+Р (4)) = 0,0256.
Сведем все в таблицу. Закон распределения случайной величины "число выигранных партий" имеет вид
Математическое ожидание
Дисперсию вычисляем по формуле (19.4)
Стандартные дискретные распределения.
Биномиальное распределение. Пусть реализуется схема опытов Бернулли: проводится n одинаковых независимых опытов, в каждом из которых событие A может появиться с постоянной вероятностью p и не появится с вероятностью
(см. лекцию 18).
Число появлений события A в этих n опытах есть дискретная случайная величина X , возможные значения которой:
0; 1; 2; ... ; m ; ... ; n.
Вероятность появления m событий A в конкретной серии из n опытов с и закон распределения такой случайной величины задается формулой Бернулли (см. лекцию 18)
 |



Числовые характеристики случайной величины X распределенной по биномиальному закону:

Если n велико (), то, при, формула (19.6) переходит в формулу
а табулированная функция Гаусса (таблица значений функции Гаусса приведена в конце 18 лекции).
На практике часто важна не сама вероятность появления m событий A в конкретной серии из n опытов, а вероятность того, что событие А появится не менее
раз и не более раз, т. е. вероятность того, что Х принимает значения
Для этого надо просуммировать вероятности
Если n велико (), то, при, формула (19.9) переходит в приближенную формулу

табулированная функция. Таблицы приведены в конце лекции 18.
При использовании таблиц надо учесть, что
Пример 1 . Автомобиль, подъезжая к перекрестку, может продолжить движение по любой из трех дорог: A, B или C с одинаковой вероятностью. К перекрестку подъезжают пять автомобилей. Найти среднее число автомашин, которое поедет по дороге A и вероятность того, что по дороге B поедет три автомобиля.
Решение. Число автомашин проезжающих по каждой из дорог является случайной величиной. Если предположить, что все подъезжающие к перекрестку автомобили совершают поездку независимо друг от друга, то эта случайная величина распределена по биномиальному закону с
n = 5 и p = .
Следовательно, среднее число автомашин, которое проследует по дороге A, есть по формуле (19.7)
а искомая вероятность при
Пример 2. Вероятность отказа прибора при каждом испытании 0,1. Производится 60 испытаний прибора. Какова вероятность того, что отказ прибора произойдёт: а) 15 раз; б) не более 15 раз?
а. Так как число испытаний 60, то используем формулу (19.8)
По таблице 1 приложения к лекции 18 находим
б . Используем формулу (19.10).
По таблице 2 приложения к лекции 18
- - 0,495
- 0,49995
Распределение Пуассона) закон редких явлений). Если n велико, а р мало (), при этом произведение пр сохраняет постоянное значение, которое обозначим л,
то формула (19.6) переходит в формулу Пуассона

Закон распределения Пуассона имеет вид:

Очевидно, что определение закона Пуассона корректно, т.к. основное свойство ряда распределения
выполнено, т.к. сумма ряда
В скобках записано разложение в ряд функции при
Теорема. Математическое ожидание и дисперсия случайной величины, распределенной по закону Пуассона, совпадают и равны параметру этого закона, т.е.
Доказательство.
Пример. Для продвижения своей продукции на рынок фирма раскладывает по почтовым ящикам рекламные листки. Прежний опыт работы показывает, что примерно в одном случае из 2 000 следует заказ. Найти вероятность того, что при размещении 10 000 рекламных листков поступит хотя бы один заказ, среднее число поступивших заказов и дисперсию числа поступивших заказов.
Решение . Здесь
Вероятность того, что поступит хотя бы один заказ, найдем через вероятность противоположного события, т.е.
Случайный поток событий. Потоком событий называется последовательность событий, происходящие в случайные моменты времени. Типичными примерами потоков являются сбои в компьютерных сетях, вызовы на телефонных станциях, поток заявок на ремонт оборудования и т. д.
Поток событий называется стационарным , если вероятность попадания того или иного числа событий на временной интервал длины зависит только от длины интервала и не зависит не зависит от расположения временного интервала на оси времени.
Условию стационарности удовлетворяет поток заявок, вероятностные характеристики которого не зависят от времени. В частности, для стационарного потока характерна постоянная плотность (среднее число заявок в единицу времени). На практике часто встречаются потоки заявок, которые (по крайней мере, на ограниченном отрезке времени) могут рассматриваться как стационарные. Например, поток вызовов на городской телефонной станции на участке времени от 12 до 13 часов может считаться стационарным. Тот же поток в течение целых суток уже не может считаться стационарным (ночью плотность вызовов значительно меньше, чем днем).
Поток событий называется потоком с отсутствием последействия , если для любых неперекрывающихся участков времени число событий, попадающих на один из них, не зависит от числа событий, попадающих на другие.
Условие отсутствия последействия - наиболее существенное для простейшего потока - означает, что заявки поступают в систему независимо друг от друга. Например, поток пассажиров, входящие на станцию метро, можно считать потоком без последействия потому, что причины, обусловившие приход отдельного пассажира именно в тот, а не другой момент, как правило, не связаны с аналогичными причинами для других пассажиров. Однако условие отсутствия последействия может быть легко нарушено за счет появления такой зависимости. Например, поток пассажиров, покидающих станцию метро, уже не может считаться потоком без последействия, так как моменты выхода пассажиров, прибывших одним и тем же поездом, зависимы между собой.
Поток событий называется ординарным , если вероятность попадания на малый интервал времени t двух или более событий пренебрежимо мала по сравнению с вероятностью попадания одного события (в этой связи закон Пуассона называют законом редких событий).
Условие ординарности означает, что заявки приходят поодиночке, а не парами, тройками и т. д. дисперсия отклонение распределение бернулли
Например, поток клиентов, входящих в парикмахерскую, может считаться практически ординарным. Если в неординарном потоке заявки поступают только парами, только тройками и т. д., то неординарный поток легко свести к ординарному; для этого достаточно вместо потока отдельных заявок рассмотреть поток пар, троек и т. д. Сложнее будет, если каждая заявка случайным образом может оказаться двойной, тройной и т. д. Тогда уже приходится иметь дело с потоком не однородных, а разнородных событий.
Если поток событий обладает всеми тремя свойствами (т. е. стационарен, ординарен и не имеет последействия), то он называется простейшим (или стационарным пуассоновским) потоком. Название "пуассоновский" связано с тем, что при соблюдении перечисленных условий число событий, попадающих на любой фиксированный интервал времени, будет распределено по закону Пуассона
Здесь - среднее число событий A , появляющихся за единицу времени.
Этот закон однопараметрический, т.е. для его задания требуется знать только один параметр. Можно показать, что математическое ожидание и дисперсия в законе Пуассона численно равны:
Пример . Пусть в середине рабочего дня среднее число запросов равняется 2 в секунду. Какова вероятность того, что 1) за секунду не поступит ни одной заявки, 2) за две секунды поступит 10 заявок?
Решение. Поскольку правомерность применения закона Пуассона не вызывает сомнения и его параметр задан (= 2), то решение задачи сводится к применении формулы Пуассона (19.11)
1) t = 1, m = 0:
2) t = 2, m = 10:
Закон больших чисел. Математическим основанием того факта, что значения случайной величины группируются около некоторых постоянных величин, является закон больших чисел.
Исторически первой формулировкой закона больших чисел стала теорема Бернулли:
"При неограниченном увеличении числа одинаковых и независимых опытов n частота появления события A сходится по вероятности к его вероятности", т.е.
где частота появления события A в n опытах,
Содержательно выражение (19.10) означает, что при большом числе опытов частота появления события A может заменять неизвестную вероятность этого события и чем больше число проведенных опытов, тем ближе р* к р. Интересен исторический факт. К. Пирсон бросал монету 12000 раз и герб у него выпал 6019 раз (частота 0.5016). При бросании этой же монеты 24000 раз он получил 12012 выпадений герба, т.е. частоту 0.5005.
Наиболее важной формой закона больших чисел является теорема Чебышева: при неограниченном возрастании числа независимых, имеющих конечную дисперсию и проводимых в одинаковых условиях опытов среднее арифметическое наблюденных значений случайной величины сходится по вероятности к ее математическому ожиданию . В аналитической форме эта теорема может быть записана так:
Теорема Чебышева кроме фундаментального теоретического значения имеет и важное практическое применение, например, в теории измерений. Проведя n измерений некоторой величины х , получают различные несовпадающие значения х 1, х 2, ..., хn . За приближенное значение измеряемой величины х принимают среднее арифметическое наблюденных значений
При этом, чем больше будет проведено опытов, тем точнее будет полученный результат. Дело в том, что дисперсия величины убывает с возрастанием числа проведенных опытов, т.к.
D (x 1) = D (x 2)=…= D (xn ) D (x ) , то
Соотношение (19.13) показывает, что и при высокой неточности приборов измерения (большая величина) за счет увеличения количества измерений можно получать результат со сколь угодно высокой точностью.
Используя формулу (19.10) можно найти вероятность того, что статистическая частота отклоняется от вероятности не более, чем на


Пример. Вероятность события в каждом испытании равна 0,4. Сколько нужно провести испытаний, чтобы с вероятностью, не меньшей, чем 0,8 ожидать, что относительная частота события будет отклоняться от вероятности по модулю менее, чем на 0,01?
Решение. По формуле (19.14)


следовательно, по таблице два приложения
следовательно, n 3932.
Дисперсия
I
Диспе́рсия (от лат. dispersio - рассеяние)
в математической статистике и теории вероятностей, наиболее употребительная мера рассеивания, т. е. отклонения от среднего. В статистическом понимании Д. есть среднее арифметическое из квадратов отклонений величин x i
от их среднего арифметического В теории вероятностей Д. случайной величины Х
называется Математическое ожидание Е (Х
- m х
) 2 квадрата отклонения Х
от её математического ожидания m х
= Е (Х
). Д. случайной величины Х
обозначается через D (X
) или через σ 2 X
. Квадратный корень из Д. (т. е. σ, если Д. есть σ 2) называется средним квадратичным отклонением (см. Квадратичное отклонение). Для случайной величины Х
с непрерывным распределением вероятностей, характеризуемым плотностью вероятности (См. Плотность вероятности) р
(х
), Д. вычисляется по формуле В теории вероятностей большое значение имеет теорема: Д. суммы независимых слагаемых равна сумме их Д. Не менее существенно Чебышева неравенство , позволяющее оценивать вероятность больших отклонений случайной величины Х
от её математического ожидания. Наличие Д. волн приводит к искажению формы сигналов при распространении их в среде. Это объясняется тем, что гармонические волны разных частот, на которые может быть разложен сигнал, распространяются с различной скоростью (подробнее см. Волны , Групповая скорость). Д. света при его распространении в прозрачной призме приводит к разложению белого света в спектр (см. Дисперсия света).![]()
![]()
Большая советская энциклопедия. - М.: Советская энциклопедия . 1969-1978 .
Синонимы :Смотреть что такое "Дисперсия" в других словарях:
дисперсия - Рассеяние чего нибудь. В математике дисперсия определяет отклонение величин от среднего значения. Дисперсия белого света приводит к его разложению на составляющие. Дисперсия звука является причиной его расплывания. Рассеяние хранимых данных по… … Справочник технического переводчика
Современная энциклопедия
- (variance) Мера разброса данных. Дисперсия множества из N членов находится путем сложения квадратов их отклонений от среднего значения и деления на N. Поэтому, если членами являются хi при i = 1, 2,..., N, a их средним является m, дисперсия… … Экономический словарь
Дисперсия - (от латинского dispersio рассеяние) волн, зависимость скорости распространения волн в веществе от длины волны (частоты). Дисперсия определяется физическими свойствами той среды, в которой распространяются волны. Например, в вакууме… … Иллюстрированный энциклопедический словарь
- (от лат. dispersio рассеяние) в математической статистике и теории вероятностей мера рассеивания (отклонения от среднего). В статистике дисперсия есть среднее арифметическое из квадратов отклонений наблюденных значений (x1, x2,...,xn) случайной… … Большой Энциклопедический словарь
В теории вероятностей наиболее употребительная мера отклонения от среднего (мера рассеяния). По английски: Dispersion Синонимы: Статистическая дисперсия Синонимы английские: Statistical dispersion См. также: Выборочные совокупности Финансовый… … Финансовый словарь
- [лат. dispersus рассеянный, рассыпанный] 1) рассеяние; 2) хим., физ. раздробление вещества на очень малые частицы. Д. света разложение белого света с помощью призмы в спектр; 3) мат. отклонение от среднего. Словарь иностранных слов. Комлев Н.Г.,… … Словарь иностранных слов русского языка
дисперсия - (варианса) показатель разброса данных, соответственный среднему квадрату отклонения этих данных от средней арифметической. Равна квадрату стандартного отклонения. Словарь практического психолога. М.: АСТ, Харвест. С. Ю. Головин. 1998 … Большая психологическая энциклопедия
Рассеяние, разброс Словарь русских синонимов. дисперсия сущ., кол во синонимов: 6 нанодисперсия (1) … Словарь синонимов
Дисперсия - характеристика рассеивания значений случайной величины, измеряемая квадратом их отклонений от среднего значения (обозначается d2). Различается Д. теоретического (непрерывного или дискретного) и эмпирического (также непрерывного и… … Экономико-математический словарь
Дисперсия - * дысперсія * dispersion 1. Рассеяние; разброс; вариация (см.). 2. Теоретико вероятностное понятие, характеризующее меру отклонения случайной величины от ее математического ожидания. В биометрической практике используется выборочная дисперсия s2 … Генетика. Энциклопедический словарь
Книги
- Аномальная дисперсия в широких полосах поглощения , Д.С. Рождественский. Воспроизведено в оригинальной авторской орфографии издания 1934 года (издательство`Известия академии наук СССР`). В…
Однако только этой характеристики ещё не достаточно для исследования случайной величины. Представим двух стрелков, которые стреляют по мишени. Один стреляет метко и попадает близко к центру, а другой… просто развлекается и даже не целится. Но что забавно, его средний результат будет точно таким же, как и у первого стрелка! Эту ситуацию условно иллюстрируют следующие случайные величины:
«Снайперское» математическое ожидание равно , однако и у «интересной личности»: – оно тоже нулевое!
Таким образом, возникает потребность количественно оценить, насколько далеко рассеяны пули (значения случайной величины) относительно центра мишени (математического ожидания). Ну а рассеяние с латыни переводится не иначе, как дисперсия .
Посмотрим, как определяется эта числовая характеристика на одном из примеров 1-й части урока:
Там мы нашли неутешительное математическое ожидание этой игры, и сейчас нам предстоит вычислить её дисперсию, которая обозначается через .
Выясним, насколько далеко «разбросаны» выигрыши/проигрыши относительно среднего значения. Очевидно, что для этого нужно вычислить разности между значениями случайной величины и её математическим ожиданием :
–5 – (–0,5) = –4,5
2,5 – (–0,5) = 3
10 – (–0,5) = 10,5
Теперь вроде бы нужно просуммировать результаты, но этот путь не годится – по той причине, что колебания влево будут взаимоуничтожаться с колебаниями вправо. Так, например, у стрелка-«любителя» (пример выше)
разности составят ![]() , и при сложении дадут ноль, поэтому никакой оценки рассеяния его стрельбы мы не получим.
, и при сложении дадут ноль, поэтому никакой оценки рассеяния его стрельбы мы не получим.
Чтобы обойти эту неприятность можно рассмотреть модули
разностей, но по техническим причинам прижился подход, когда их возводят в квадрат. Решение удобнее оформить таблицей:
И здесь напрашивается вычислить средневзвешенное
значение квадратов отклонений. А это ЧТО такое? Это их математическое ожидание
, которое и является мерилом рассеяния:
![]() – определение
дисперсии. Из определения сразу понятно, что дисперсия не может быть отрицательной
– возьмите на заметку для практики!
– определение
дисперсии. Из определения сразу понятно, что дисперсия не может быть отрицательной
– возьмите на заметку для практики!
Вспоминаем, как находить матожидание. Перемножаем квадраты разностей на соответствующие вероятности (продолжение таблицы)
:
– образно говоря, это «сила тяги»,
и суммируем результаты:
Не кажется ли вам, что на фоне выигрышей результат получился великоватым? Всё верно – мы возводили в квадрат, и чтобы вернуться в размерность нашей игры, нужно извлечь квадратный корень. Данная величина называется средним квадратическим отклонением
и обозначается греческой буквой «сигма»:
Иногда это значение называют стандартным отклонением .
В чём его смысл? Если мы отклонимся от математического ожидания влево и вправо на среднее квадратическое отклонение:![]()
– то на этом интервале будут «сконцентрированы» наиболее вероятные значения случайной величины. Что мы, собственно, и наблюдаем:
Однако так сложилось, что при анализе рассеяния почти всегда оперируют понятием дисперсии. Давайте разберёмся, что она означает применительно к играм. Если в случае со стрелками речь идёт о «кучности» попаданий относительно центра мишени, то здесь дисперсия характеризует две вещи:
Во-первых, очевидно то, что при увеличении ставок, дисперсия тоже возрастает. Так, например, если мы увеличим в 10 раз, то математическое ожидание увеличится в 10 раз, а дисперсия – в 100 раз (коль скоро, это квадратичная величина) . Но, заметьте, что сами-то правила игры не изменились! Изменились лишь ставки, грубо говоря, раньше мы ставили 10 рублей, теперь 100.
Второй, более интересный момент состоит в том, что дисперсия характеризует стиль игры. Мысленно зафиксируем игровые ставки на каком-то определённом уровне , и посмотрим, что здесь к чему:
Игра с низкой дисперсией – это осторожная игра. Игрок склонен выбирать самые надёжные схемы, где за 1 раз он не проигрывает/выигрывает слишком много. Например, система «красное/чёрное» в рулетке (см. Пример 4 статьи Случайные величины ) .
Игра с высокой дисперсией. Её часто называют дисперсионной игрой. Это авантюрный или агрессивный стиль игры, где игрок выбирает «адреналиновые» схемы. Вспомним хотя бы «Мартингейл» , в котором на кону оказываются суммы, на порядки превосходящие «тихую» игру предыдущего пункта.
Показательна ситуация в покере: здесь есть так называемые тайтовые игроки, которые склонны осторожничать и «трястись» над своими игровыми средствами (банкроллом) . Неудивительно, что их банкролл не подвергается значительным колебаниям (низкая дисперсия). Наоборот, если у игрока высокая дисперсия, то это агрессор. Он часто рискует, делает крупные ставки и может, как сорвать огромный банк, так и програться в пух и прах.
То же самое происходит на Форексе, и так далее – примеров масса.
Причём, во всех случаях не важно – на копейки ли идёт игра или на тысячи долларов. На любом уровне есть свои низко- и высокодисперсионные игроки. Ну а за средний выигрыш, как мы помним, «отвечает» математическое ожидание .
Наверное, вы заметили, что нахождение дисперсии – есть процесс длительный и кропотливый. Но математика щедрА:
Формула для нахождения дисперсии
Данная формула выводится непосредственно из определения дисперсии, и мы незамедлительно пускаем её в оборот. Скопирую сверху табличку с нашей игрой:
и найденное матожидание .
Вычислим дисперсию вторым способом. Сначала найдём математическое ожидание – квадрата случайной величины . По определению математического ожидания
:
В данном случае:
Таким образом, по формуле:
Как говорится, почувствуйте разницу. И на практике, конечно, лучше применять формулу (если иного не требует условие).
Осваиваем технику решения и оформления:
Пример 6

Найти её математическое ожидание, дисперсию и среднее квадратическое отклонение.
Эта задача встречается повсеместно, и, как правило, идёт без содержательного смысла.
Можете представлять себе несколько лампочек с числами, которые загораются в дурдоме с определёнными вероятностями:)
Решение
: Основные вычисления удобно свести в таблицу. Сначала в верхние две строки записываем исходные данные. Затем рассчитываем произведения , затем и, наконец, суммы в правом столбце:
Собственно, почти всё готово. В третьей строке нарисовалось готовенькое математическое ожидание: ![]() .
.
Дисперсию вычислим по формуле:
И, наконец, среднее квадратическое отклонение:
– лично я обычно округляю до 2 знаков после запятой.
Все вычисления можно провести на калькуляторе, а ещё лучше – в Экселе:
вот здесь уже трудно ошибиться:)
Ответ :
Желающие могут ещё более упростить свою жизнь и воспользоваться моим калькулятором (демо) , который не только моментально решит данную задачу, но и построит тематические графики (скоро дойдём) . Программу можно скачать в библиотеке – если вы загрузили хотя бы один учебный материал, либо получить другим способом . Спасибо за поддержку проекта!
Пара заданий для самостоятельного решения:
Пример 7
Вычислить дисперсию случайной величины предыдущего примера по определению.
И аналогичный пример:
Пример 8
Дискретная случайная величина задана своим законом распределения:

Да, значения случайной величины бывают достаточно большими (пример из реальной работы) , и здесь по возможности используйте Эксель. Как, кстати, и в Примере 7 – это быстрее, надёжнее и приятнее.
Решения и ответы внизу страницы.
В заключение 2-й части урока разберём ещё одну типовую задачу, можно даже сказать, небольшой ребус:
Пример 9
Дискретная случайная величина может принимать только два значения: и , причём . Известна вероятность , математическое ожидание и дисперсия .
Решение
: начнём с неизвестной вероятности. Так как случайная величина может принять только два значения, то сумма вероятностей соответствующих событий:
и поскольку , то .
Осталось найти …, легко сказать:) Но да ладно, понеслось. По определению математического ожидания:![]() – подставляем известные величины:
– подставляем известные величины:
![]() – и больше из этого уравнения ничего не выжать, разве что можно переписать его в привычном направлении:
– и больше из этого уравнения ничего не выжать, разве что можно переписать его в привычном направлении:![]()

или: ![]()
О дальнейших действиях, думаю, вы догадываетесь. Составим и решим систему:
Десятичные дроби – это, конечно, полное безобразие; умножаем оба уравнения на 10:
и делим на 2:
Вот так-то лучше. Из 1-го уравнения выражаем:![]() (это более простой путь)
– подставляем во 2-е уравнение:
(это более простой путь)
– подставляем во 2-е уравнение:
![]()
Возводим в квадрат
и проводим упрощения:
Умножаем на :
В результате получено квадратное уравнение
, находим его дискриминант:
– отлично!
и у нас получается два решения:
1) если ![]() , то
, то ![]() ;
;
2) если ![]() , то .
, то .
Условию удовлетворяет первая пара значений. С высокой вероятностью всё правильно, но, тем не менее, запишем закон распределения:
и выполним проверку, а именно, найдём матожидание: