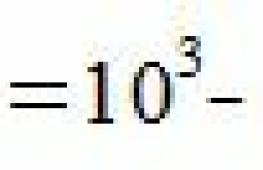Экономико-математические методы прогнозирования. Методика математического моделирования программы развития сельскохозяйственного предприятия
Существуют различные методы прогнозирования показателей технического уровня, среди которых можно выделить эвристическое и математическое прогнозирование. Общим в этих методах является наличие неопределенности, связанной с будущей ситуацией.
Эвристические методы основаны на использовании мнений специалистов в данной области техники и обычно применяются для прогнозирования развития процессов и объектов при невозможности формализации в данный момент.
Математические методы в зависимости от вида математического описания объектов прогнозирования и способов определения неизвестных параметров условно подразделяются на методы моделирования процессов, описываемых дифференциальными уравнениями, и методы экстраполяции, или статистические. Ко второй группе относятся методы, определяющие прогнозируемые параметры объекта на основании статистических данных. В качестве математического аппарата при статистическом прогнозировании наиболее часто применяется метод максимального правдоподобия и, в частности, его разновидность — метод наименьших квадратов. Математические зависимости, построенные методом наименьших квадратов, могут быть линейными, квадратичными или по-линомными.
Завершающим этапом эвристических и математических прогнозных исследований является логический анализ, который предусматривает изучение тенденций развития прогнозируемого объекта, анализ результатов прогнозирования подобных объектов и оценка полученных результатов.
Эвристическое прогнозирование
Эвристическое прогнозирование относится к наиболее давним и распространенным не только в технике, но и повседневной жизни методам. Его достоинством считается возможность избегать грубых ошибок, особенно в области скачкообразных изменений прогнозируемой характеристики, при условии, что к исследованию привлекаются высококвалифицированные специалисты в данной области. Однако этот метод является субъективным и трудоемким.
Главный результат эвристического прогнозирования заключается в определении новых направлений развития и их возможностей. При этом необходимо иметь в виду, что восприятию нового и определению перспективных направлений могут препятствовать психологические аспекты. Это, в первую очередь, профессиональная ограниченность специалистов узкого профиля, которые «знают все ни о чем», или, наоборот, широкого профиля — «ничего обо всем». Также может стать помехой концентрация внимания на известных явлениях, влияние господствующего направления общественной мысли, трудность восприятия отрицательных выводов, склонность к преувеличению плохого и т. д. Не случайно многие открытия, опередившие свое время, не были восприняты современниками.
Основными этапами практического применения эвристического прогнозирования являются подбор экспертов, организация опросов и обработка полученных результатов. Эвристическое прогнозирование основано на усредненной оценке мнений группы экспертов. Поэтому главным условием такого исследования можно считать именно подбор экспертов, от компетентности которых зависит качество результата. Практически не существует методов оценки компетентности экспертов. Поэтому обычно эксперты сами оценивают свою компетентность и компетентность своих коллег.
С развитием и совершенствованием электронно-вычислительной техники роль эвристических методов заметно снижается.
Математическое прогнозирование
Математическое прогнозирование заключается в использовании имеющихся характеристик прогнозируемого объекта, обработке этих данных математическими методами, получении их математической зависимости от времени и других известных независимых переменных и вычислении с помощью найденной зависимости характеристик объекта в заданный момент времени при заданных значениях других независимых переменных.
Метод математического прогнозирования характеризуется объективностью и высокой точностью получаемых результатов при правильном выборе математической модели. К числу основных этапов математического прогнозирования относятся:
1) сбор и подготовка исходных данных (статистика);
2) выбор и обоснование математической модели прогнозируемого объекта;
3) обработка статистических данных для определения неизвестных параметров модели;
4) выполнение расчетов и анализ полученных результатов.
Оценка прогнозируемого параметра может быть точечной или интервальной, т. е. состоящей в определении доверительного вероятностного интервала значений параметра. Интервальная оценка достаточно хорошо отражает точность прогнозирования.
также к определению траектории развития после скачка.
В соответствии с законом эволюционного и скачкообразного развития техники, прогнозирование скачков неотделимо от прогнозирования эволюционного развития до скачка и после него. Системный подход к прогнозированию технического уровня машин на основе сопоставления циклов развития и потребностей позволяет определить не только достижения того или иного параметра, но и рассчитать время появления нового поколения техники, период его возможного существования. На рисунке 1 показаны характерные взаимосвязи и чередование поколений техники. Здесь отмечены участки, соответствующие стадиям жизненного цикла поколения техники: 1 — перспективная; 2 — прогрессивная; 3 — новая; 4 — модернизируемая; 5 — морально устаревшая.
При помощи корреляционной функции случайных процессов появления информации об объекте, содержащейся в патентных материалах, и появления техники с новыми значениями показателей технического уровня можно определить время т начала освоения нового поколения техники, которое для каждого конкретного образца складывается из времени, затрачиваемого на научно-исследовательские, опытно-конструкторские работы, и времени на освоение в производстве.
Смена поколений
Смена поколений техники происходит согласно объективному закону прогрессивной эволюции техники при наличии необходимого научно-технического уровня и социально-экономической целесообразности. Так, огромный прорыв в развитии техники, в том числе фасовочно-упа-ковочной, произошел после появления современных микропроцессоров, сопоставимых по своим возможностям с человеческим мозгом. Это позволило специалистам в конце XX века сделать прогноз развития техники, согласно которому, по степени автоматизации в мире будет создано всего шесть поколений машин.
Программируемые машины-автоматы четвертого поколения уже нашли широкое распространение в технике, в том числе фасовочно-упаковочной. На очереди — создание самообучающихся и самонастраивающихся машин-автоматов пятого поколения, отдельные элементы которых уже появляются в автоматах четвертого поколения. Уже создано несколько машин-автоматов с признаками пятого поколения. Например, машины с автоматической настройкой на режимы розлива жидкостей различной вязкости, упаковки штучных предметов разных размеров, самодиагностикой и т. д. Машины-автоматы шестого поколения — это машины искусственного интеллекта, которые по техническим характеристикам могут существенно отличаться от автоматов предыдущих поколений. По всей видимости, умные и многофункциональные машины в мгновение ока подстроятся под грядущие перемены. Высокоскоростные комплексные линии, которые еще недавно соответствовали нормам, заменяются менее скоростными, дающими большую маневренность действий. Тенденция к уменьшению объема партий сведет время перемен практически к нулю. Должны быть разработаны такие производственные системы, для которых изменения в бизнес-процессе являются нормой. Нужны системы, основанные на принципах искусственного интеллекта, распространяющегося по всей самоорганизующейся сети. Таким образом, искусственный интеллект должен присутствовать в упаковочном оборудовании, а само оборудование должно быть многофункциональным.
Определение технического уровня
Прогнозирование непосредственно связано с определением технического уровня упаковочной техники. Статистические прогнозные исследования позволяют установить достигнутый мировой технический уровень и опре делить параметры перспективного базового образца. Согласно закону корреляции параметров, любой объект техники характеризуется набором параметров, находящихся в корреляционной зависимости от главного параметра. Таким главным параметром для большинства существующих фасовочно-упаковочных машин служит их производительность. В машинах пятого и шестого поколения главным параметром могут быть другие показатели, например, универсальность и многофункциональность, быстрота переналадки и т. д.
От поколения к поколению техника становится сложнее в силу действия объективного закона возрастания сложности технических объектов. Трудность определения научно-технического уровня упаковочной техники заключается в выборе перспективного образца для сравнения показателей. Конкуренция среди производителей упаковочной техники и, как следствие, постоянные усовершенствования существующих моделей, применение сервоприводов и дозаторов, управляемых микропроцессорами, способствовали появлению поколения универсальных и многофункциональных машин-автоматов, использующих конструктивные элементы машин предыдущих поколений. В результате стало практически невозможно выбрать для определения достигнутого уровня некоторых объектов упаковочный техники соответствующий аналог для сравнения показателей.
Существуют различные подходы к решению этой проблемы. Так, оценивать технический уровень воротниковых упаковочных машин предлагается с помощью наглядного и весьма значимого показателя — теоретической производительности их упаковочной части, исходя из того, что ее рост лучшим образом отражает развитие этого вида оборудования. При этом рекомендуется классифицировать любое фасовочно-упаковочное оборудование по производительности, разделив, в частности, воротниковое оборудование на пять классов, и сравнивать между собой машины одного класса.
Однако деление на классы представляется довольно условным и не устраняет отмеченные выше затруднения, возникающие при выборе аналогов для сравнения. Кроме того, уже в недалекой перспективе в одном по производительности классе могут оказаться фасовочно-упаковочные машины четвертого и шестого поколений разного назначения, сравнивать которые менее корректно, чем автомобили разной грузоподъемности.
Профессор В. Панишев рекомендует для оценки мирового уровня упаковочной техники включать в сравнительную таблицу как можно больше реально существующих и функционирующих единиц оборудования и проводить ранжирование общих, классификационных и отраслевых показателей путем сопоставления каждого из них с существующими показателями технического уровня изделий по данным технических характеристик машин, техническим условиям и другим документам («Тара и упаковка», № 3/1995).
Мы предлагаем для оценки технического уровня реально существующих фасовочно-упаковочных машин, для которых невозможно выбрать подходящий аналог, использовать закон корреляции параметров. В качестве примера были приведены отдельные показатели вертикальных воротниковых фасовочно-упаковочных автоматов, представляемые отечественными и зарубежными производителями, и по этим данным построены статистические зависимости этих показателей от производительности (PG, № 1—2/2004).
Аппроксимация этих статистических данных прямыми линиями методом наименьших квадратов (рисунок 2) показывает весьма высокую степень корреляции рассматривае мых параметров от производительности машин и, несмотря на приблизительность некоторых данных, хорошую плотность укладки точек на аппроксимирующих прямых. В этом примере не ставилась задача определения технического уровня конкретных объектов. Для решения такой задачи требуется значительно больше уточненных исходных данных.
Построенные зависимости подтверждают принципиальную возможность выполнить оценку мирового технического уровня конкретного объекта по отдельным показателям, отражающим этот уровень. Технический уровень по оцениваемому показателю может соответствовать среднему отечественному или мировому уровню при совпадении этого показателя с показателями на соответствующей аппроксимирующей прямой линии. На этих графиках, построенных по данным 3—4-летней давности, имеет место заметное расхождение уровня по отдельным показателям отечественных и зарубежных машин. Аналогичные показатели новых вертикальных воротниковых фасовочно- упаковочных автоматов по материалам международных выставок 2004 г. приведены в таблице 1.
Если дополнить соответствующие корреляционные зависимости новыми данными, очевидной становится тенденция к сближению отдельных показателей технического уровня отечественных и зарубежных автоматов.
На рисунке 3 отмечены показатели таблицы 1 и представлены построенные ранее на рисунке 2 аппроксимирующие прямые зависимости установленной мощности и массы машин от производительности для зарубежных автоматов (прямые 2).
Представленные на рисунке 3 зависимости подтверждают наличие корреляции и свидетельствуют о достаточно заметном сближении рассматриваемых параметров отечественных и зарубежных фасовочно-упаковочных автоматов последних моделей, что, несомненно, указывает на определенную тенденцию повышения технического уровня отечественной фасовоч-но-упаковочной техники.
Юрашев Виталий Викторович к. ф.-м. н., научный руководитель фирмы «Градиент»
Шелест Игорь Владимирович системный архитектор «Инфосистемы Джет»
Прогноз в бизнесе важен из-за возможного использования его для эффекта стабилизации. Разумные прогнозы побуждают людей действовать более рационально и предупреждают их «сверхреакцию» в сторону пессимизма или оптимизма. Хороший прогноз обеспечивает фирме принятие рациональных решений относительно производимых фирмой товаров или услуг. Отсутствие прогноза заставляет руководство фирмы предпринимать излишние меры предосторожности.
Методы прогноза обычно требуют больших затрат времени и денег. Однако бизнесмен нуждается в методах, которые не требуют сложных умозаключений в повседневной работе и могут быть представлены в виде программ. Необходимо найти методы прогнозирования без детального индивидуального анализа. К тому же желательно, чтобы знания ситуации на рынке, которыми обладают люди, постоянно работающие на нем, были использованы в подобных моделях.
Поскольку прогнозирование является трудной проблемой, то очевидно, что фирма должна иметь несколько серий прогнозов, отличных от простого описательного прогноза. Это поможет принимать более решительные действия, результатом которых является рост прибыли, повышение эффективности работы организации и роста ее престижа.
Исходные данные для составления прогноза с использованием временных рядов обычно представляют собой результаты выборочных наблюдений переменных - либо интенсивности (например, спрос на продукцию), либо состояния (например, цена). Решения, которые должны приниматься в данный момент, скажутся в дальнейшем по прошествии некоторого промежутка времени, величина которого может быть прогнозируемой.
Временные ряды представляют собой упорядоченные во времени данные. В соответствии с этим мы будем впредь обозначать период времени через t, а соответствующее ему значение данных через y(t). Отметим, что членами временного ряда являются либо суммы, либо числовая информация, полученная в определенный момент времени. Например, сумма недельных продаж в магазине, получаемая в конце каждой недели в течение года, образует временной ряд.
Тренд означает общее направление и динамику временного ряда. В этом определении ударение делается на понятии «общее направление», поскольку основную тенденцию необходимо отделить от краткосрочных колебаний, представляющих собой циклические и сезонные колебания. Примеры циклических колебаний: цены на промышленное сырье, курсы акций, объемы продаж в оптовой и розничной торговле и др. Сезонные колебания встречаются во временных рядах, описывающих продажи, производство, занятость и др. Важную роль в сезонных колебаниях играют погодные условия, мода, стиль и т. д. Особо отметим, что нерегулярные или случайные колебания временных рядов не подчиняются никакой закономерности и не существует теории, способной предсказать их поведение.
С точки зрения выработки правильного решения руководством фирмы, включение периодических (циклических и сезонных) колебаний в общую модель может повысить эффективность прогноза и позволит предсказать ожидаемые высокие и низкие значения прогнозируемых переменных. При этом нужно иметь в виду, что «деловые» или экономические циклы нельзя воспроизвести с точностью, позволяющей на практике делать выводы о будущих подъемах и спадах, исходя из анализа прошлого.
В работе представлены линейный, циклический и «экспоненциальный» тренды. Несколько слов об экспоненциальном тренде. Анализ жизненного цикла товаров, услуг, инноваций и размышления о процессах, происходящих вокруг, показали, что модель развития и гибели биологических систем является эффективным инструментом для изучения многих явлений в бизнесе. Причем как и в бизнесе, показатели функционирования биологической системы во времени не линейны на всех этапах ее развития. Были промоделированы упомянутые выше жизненные циклы, и было установлено, что их эластичность по времени является линейной функцией. Коэффициенты этой функции позволяют учитывать не только нелинейные механизмы жизненных циклов, но и прогнозировать их появление. В результате мы получили тренд,который назвали «экспоненциальным», поскольку в него входит временная экспонента.
Рассмотрим временной ряд y(1), y(2),...(y(i),...y(T). Требуется представить функцию, для которой задан этот ряд, тригонометрическим полиномом. Периодические компоненты полинома неизвестны. Достоинство такой модели состоит в том, что она обеспечивает стабильность прогноза за счет перебора частот. Коэффициенты вычисляются с использованием всего набора данных.
На практике подобная модель оказывается сложной для пользователя. Поэтому была разработана компьютерная программа. Проверка на соответствие предыстории проводится по методу наименьших квадратов (см.: Таха А. Исследование операций. М.: Вильямс, 2005). Во многих случаях изменения в изучаемом процессе можно предвидеть заранее и включить их в представленную модель прогноза. Ведь опытные руководители могут предсказать характер изменений. В программе заложено согласование трендов за счет оптимального выбора частот в представленном ряде. Для корректировки прогноза можно варьировать не только тренды, но и учитывать результаты субъективного прогноза.
Будем искать тренд в виде: Y(t) = C + Asin(wt) + Bcos(wt).
Поскольку значения этой функции в точках 1, 2, ... Т известны, то мы получаем систему из Т линейных уравнений относительно коэффициентов А, В, С, w - параметр.
Решаем эту систему методом наименьших квадратов (Т>3) и получаем значения коэффициентов А, В, С, зависящих от w. Необходимо выбрать значения w таким образом, чтобы значения тренда наилучшим образом приближались бы к значениям временного ряда. Оптимизация проводится методом последовательных приближений. Первоначальное значение w, которое является началом последовательных приближений, находится по формулам, представленным, например, в справочнике по математике авторов Г. Корн, Т. Корн, (М.: Наука, 1989. Гл. 20).
Вычитаем из фактических (т. е. заданных изначально в виде членов временного ряда) значений y(1), y(2),...y(i),....y(t) найденные теоретические значения y(t) в моменты времени t =1, 2,...,i,...Т. Для полученных данных (считая их фактическими, т. е. членами временного ряда) повторяем указанную выше процедуру.
Точность прогноза 1-3%, колеблется иногда до 5-10%. Все зависит от наличия шумов, которые могут существенно повлиять на прогноз. Если ретроспективный ряд большой, то программа хорошо выделяет регулярные составляющие процесса. При незначительном временном ряде ретроспективы (до 5-8 значений) нужно пользоваться экспоненциальным сглаживанием. В основе метода экспоненциального сглаживания лежит скользящая средняя. Но он устраняет недостаток метода скользящей средней, который состоит в том, что все данные, используемые для вычисления среднего, имеют одинаковый вес. В частности, метод экспоненциального сглаживания присваивает больший весовой коэффициент самому последнему наблюдению. Он, также как и метод, представленный в этой работе, особенно эффективен при прогнозе временных рядов с циклическими колебаниями без сильных случайных колебаний (см.: Таха А. Исследование операций).
Приведем пример расчета прогнозируемого объема продаж (табл. 1, 2).
Таблица 1. Исходные данные

Таблица 2. Расчет прогноза с использованием синусоидального тренда

Результаты расчета представлены в виде графиков на рисунке 1(теоретическая функция – черный штрих, исходные данные – черный цвет, тренд – серый цвет).

Рис. 1. Расчет прогнозируемого объема продаж по синусоидальному тренду
Приведем пример использования экспоненциального тренда для расчета прогноза сбыта.
В данном примере рассмотрено изменение объема продаж во время и после рекламной кампании (табл. 3, 4).
Таблица 3. Исходные данные

Таблица 4. Расчет прогноза с использованием экспоненциального тренда

Результаты расчета представлены в виде графиков на рисунке 2 (теоретическая функция - серый штрих, исходные данные - черный цвет, тренд - серый цвет).

Рис. 2. Расчет прогнозируемого объема продаж по экспоненциальному тренду
Разработанный нами программный продукт, адаптированный для работы в конкретных условиях, обладает универсальностью, надежностью и устойчивостью к изменению условий. Кроме того, и это существенно, можно увеличить число решаемых задач. Так, например, при прогнозировании объемов продаж можно решить проблему влияния каждого показателя (рекламы, выставок, интернета) на величину прибыли.
Одно из достоинств проекта - его дешевизна. Поэтому можно сравнить получаемые результаты с теми, которые были получены другими методами. Их различие даст повод руководству провести более глубокие исследования.
Программа проста в применении, достаточно ввести в программу необходимые данные из информационного поля. Единственная трудность может быть в получении анкетных данных. Трудности возникают при создании информационного поля, в котором предстоит работать.
Здесь все зависит от условий, в которых должны быть получены данные (в полевых или лабораторных). Возможности экспертов построить квазиинформационное поле упрощают работу на предварительном этапе исследования, однако при этом теряется «полевая» изюминка проекта.
Ценность проекта также в мобильности решения поставленных задач, быстрой реакции на изменения окружающей среды, легкой коррекции изменений и дополнений при работе над конкретной задачей.
МАТЕМАТИЧЕСКИЕ МЕТОДЫ ПРОГНОЗИРОВАНИЯ В УПРАВЛЕНИИ ПРЕДПРИЯТИЕМ
Ковальчук Светлана Петровна
студентка 4 курса, кафедра экономической кибернетики ВНАУ, г. Винница
Коляденко Светлана Васильевна
научный руководитель, докт.экон.наук, профессор ВНАУ, г. Винница
Введение. В условиях развития рыночных отношений для обеспечения эффективного хозяйствования предприятия, принятия управленческих решений необходимо проведение глубокого анализа экономических показателей его деятельности в динамике, что дает возможность с помощью методов прогнозирования по мере поступления новой информации выявить закономерности изменений во времени и определить обоснованные пути развития объекта управления.
Анализ последних исследований и публикаций. Вопрос прогнозирования исследовались в научных работах таких известных отечественных и зарубежных экономистов, как И. Ансофф, В. Геець, Г. Добров, М. Долишний, А. Илишев, М. Кизим, В. Кучерук, В. Лисичкин, А. Мельник, М. Мескон, З. Микитишин, И. Михасюк, Б. Панасюк, М. Портер, Г.Савицкая, Р. Сайфулин и другие. Тем не менее существует объективная необходимость дальнейшего исследования методических и прикладных основ прогнозирования деятельности предприятий с учетом особенностей становления рыночной экономики.
Целью исследования является систематизация математических методов экономического прогнозирования в управлении предприятием, определение их особенностей, заданий и принципов.
Основные результаты исследования. Прогноз (от греч. prognosis – предвидение) – это попытка определить состояние некоторого явления или процесса в будущем. Процесс формирования прогноза называют прогнозированием. Прогнозирование в управлении предприятием – это научное обоснование возможных количественных и качественных изменений его состояния, уровня развития в целом, отдельных направлений деятельности в будущем, а также альтернативных способов и сроков достижения ожидаемого состояния.
Процесс прогнозирования всегда основывается на определенных принципах:
- целеустремленность – содержательное описание поставленных исследовательских задач;
- системность – построение прогноза на основании системы методов и моделей, которые характеризуются определенной иерархией и последовательностью;
- научная обоснованность – всесторонний учет требований объективных законов развития общества, использование мирового опыта;
- многоуровневое описание – описание объекта как целостного явления и вместе с тем как элемента более сложной системы;
- информационное единство – использование информации на одинаково равное обобщения и целостности признаков;
- адекватность объективным закономерностям развития – выявление и оценка устойчивых взаимосвязей и тенденций развития объекта;
- последовательное решение неопределенности – поэтапная процедура продвижения от выявления целей и сложившихся условий к определению возможных направлений развития;
- альтернативность – выявление возможности развития объекта при условии разных траекторий, разнообразных взаимосвязей и структурных соотношений .
Прогнозирование выполняет три основных функции и имеет три стадии:
- предвидение возможных тенденций изменений в будущем, выявление закономерностей, тенденций, факторов, обуславливающих эти изменения (исследовательская стадия);
- выявление альтернативных вариантов влияния на развитие объекта в результате принятия тех или иных решений, оценка последствий реализации этих решений (стадия обоснования управленческих решений);
- оценка результатов выполнения решений, непредвиденных изменений внешней среды, чтобы своевременно скоординировать решение (стадия наблюдения и коррекции) .
Эти три функции и три стадии взаимно переплетены, итеративно повторяются и являются составными элементами управленческой деятельности в любой сфере.
Качество прогнозов в значительной мере зависит от методов прогнозирования, которыми называют совокупность приемов и оценок, которые дают возможность на основании анализа прошлых (ретроспективных) внутренних и внешних связей, присущих объекту, а также их изменений с определенной вероятностью сделать вывод относительно будущего развития объекта .
По принципу информационного обоснования различают такие методы:
І. Фактографические методы, которые базируются на фактическом информационном материале об объекте прогнозирования и его прошлом развитии:
- статистические методы: экстраполяции и интерполяции, корреляционно-регрессионный анализ, факторные модели;
- аналогии: математические, исторические;
- опережающие методы прогнозирования, которые основываются на определенных принципах специальной обработки научно-технической информации и реализуют в прогнозе ее свойство опережать развитие научно-технического прогресса (методы анализа динамики патентования, публикационные методы прогнозирования).
ІІ. Экспертные методы, которые базируются на субъективной информации, которую предоставляют специалисты-эксперты в процессе систематизированных процедур выявления и обобщение их мысли относительно будущего состояния дел. Для этих методов характерно предвидение будущего на основе как рациональных доказательств, так и интуитивных знаний. Они, как правило, имеют качественный характер. К этим методам принадлежат такие:
- прямые: экспертного опрашивания; экспертного анализа, когда эксперт или коллектив экспертов сами ставят и решают вопросы, которые ведут к поставленной цели; с обратной связью; метод «комиссий», что может означать организацию «круглого стола» и других подобных мероприятий, в пределах которых происходит согласование мыслей экспертов; метод «мозговых атак», для которого характерны коллективная генерация идей и творческое решение проблем; метод Дельфи, что предусматривает проведение анкетных опрашиваний специалистов избранной области знаний.
ІІІ. Комбинированные методы со смешанной информационной основой, в которой как первичную используют фактографическую и экспертную информацию: балансовые модели; оптимизационные модели.
Одними из наиболее распространенных методов прогнозирования являются эконометрические методы – это комплекс экономических и математических научных дисциплин, которые изучают экономические процессы и системы. Эконометрическая модель представляет собой систему регрессионных (стохастических) уравнений и тождественностей. Коэффициенты уравнений определяются методами математической статистики на основе конкретной экономико-статистической информации, а наиболее распространенным методом количественной оценки коэффициентов есть метод наименьших квадратов с его модификациями. Эконометрические уравнения выражают зависимость исследуемых переменных от изменения других показателей, в том числе и от состояния этих переменных в прошлом. Тождественности же устанавливают взаимозависимость между переменными, отображающими структуру используемой статистики .
Математическую платформу эконометрических моделей составляют методы корреляционного и регрессионного анализа. Корреляционный анализ дает возможность отобрать наиболее существенные факторы и построить соответствующее уравнение регрессии .
Корреляционный анализ обеспечивает: измерение степени связи двух и больше переменных; выявление факторов, наиболее существенно влияющих на зависимую переменную; определение прежде неизвестных причинных связей (корреляция непосредственно не раскрывает причинных связей между явлениями, но определяет числовое значение этих связей и вероятность суждений относительно их существования). Основными средствами анализа есть парные, частные и множественные коэффициенты корреляции.
Регрессионный анализ разрешает решать такие задачи:
- установление форм зависимости между одной эндогенной и одной или несколькими экзогенными переменными (положительная, отрицательная, линейная, нелинейная). Эндогенная переменная обычно обозначается Y , а экзогенная (экзогенные), которая еще иначе называется регрессором, – X ;
- определение функции регрессии. Важно не только указать общую тенденцию изменения зависимой сменной, а и выяснить степень влияния на зависимую переменную главных факторов, если бы остальные (второстепенные, побочные) факторы не изменялись (находились на том самом среднему уровне) и были исключены случайные элементы;
- оценивание неизвестных значений зависимой сменной.
Согласно цели прогнозирования определяется совокупность и структура переменных, которые входят в модель. На основе теоретического анализа взаимосвязей переменных формируется система уравнений, и оцениваются параметры уравнений регрессии. В результате рассмотрения разных вариантов структур уравнений в системе остаются те из них, которые имеют наилучшие качественные характеристики и не противоречат экономической теории. И последний этап построения модели содержит проверку ее способности воссоздавать динамику прошлого экономического развития, т.е. имитацию на модели базового периода, который разрешает оценить ее качество.
Объектами прогнозирования в управлении предприятием могут быть: спрос, производство продукции (выполнение услуг), объем продаж, потребность в материальных и трудовых ресурсах, затрат производства и реализации продукции, цены, доходы предприятия, его техническое развитие.
Субъектами прогнозирования являются планово-экономические отделы предприятия, маркетинговые и технические отделы.
Разработка планов-прогнозов (на перспективу, краткосрочные (год, квартал, месяц) и оперативные (сутки, декада)) происходит как в целому по предприятию, так и по его структурным подразделениям: цехам, участкам, службам. При прогнозировании показателей целесообразно использовать следующую систему методов: экспертные оценки, факторные модели, методы оптимизации, нормативный метод.
Выводы. Для принятия решения необходимо иметь достоверную и полную информацию, на основе которой формируется стратегия производства и сбыта продукции. В связи с этим повышается роль прогнозов, нужное расширение системы и совершенствование методов прогнозирования, применяемых на практике. Особое внимание должно уделяться прогнозированию спроса на продукцию, расходов производства, цен и прибыли. Для этого проводятся исследование внутреннего и мирового рынков, осуществляется анализ эластичности спроса.
Список литературы:
- Лугинин О.Е. Эконометрия: учеб. пособие для студ. высших учеб. завед. – 2-е изд., перераб. и доп. – К. : Центр учебной литературы, 2008. – 278 с.
- Орлов А.И. Эконометрика. – М.: Экзамен, 2002. – 576 с.
- Присенко Г. В., Равикович Є. И. Прогнозирование социально-экономических процессов: учебн. пособ. – К.: КНЭУ, 2005. – 378 с.
- Стеценко Т. О., Тищенко О. П. Управление региональнойэкономикой: учебн. пособ. ГВУЗ Киев. нац. экон. ун-т им. В. Гетьмана. – К. : КНЭУ, 2009. – 471 с.
- Яковец Ю.В. Прогнозирование циклов и кризисов. – M.: МФК, 2000. – С. 42.
Приложение 1. МЕТОДЫ СТАТИСТИЧЕСКОГО АНАЛИЗА И ПРОГНОЗИРОВАНИЯ В БИЗНЕСЕ
4. Математический инструментарий прогнозирования
Математические методы и модели, используемые в задачах стохастического анализа и прогнозирования в бизнесе, могут относиться к самым различным разделам математики: к регрессионному анализу, анализу временных рядов, формированию и оцениванию экспертных мнений, имитационному моделированию, системам одновременных уравнений, дискриминантному анализу, логит- и пробит-моделям, аппарату логических решающих функций, дисперсионному или ковариационному анализу, анализу ранговых корреляций и таблиц сопряженности и т. д. Однако все они объединены тем, что представляют собой различные подходы к решению центральной проблемы многомерного статистического анализа и эконометрики – проблемы статистического исследования зависимостей , которая, как раз, и является базовой проблемой статистического анализа и прогнозирования в бизнесе (ее общая формулировка была приведена в п. 2).
В п. 1 уже было замечено, что среди p + k + l + m компонент анализируемого многомерного признака могут быть как количественные, так и ординальные и номинальные переменные. Упомянутые выше подходы к решению центральной проблемы многомерного статистического анализа формировались именно с учетом природы исследуемых переменных. Соответствующая специализация этих подходов отражена в табл. 4. В ней же даны ссылки на литературные источники, в которых можно найти достаточно полное описание этих подходов.
Таблица 4.
|
Природа результирующих показателей |
Природа объясняющих переменных |
Название обслуживающих разделов многомерного статистического анализа |
Литературные источники |
|
Количественная |
Количественная |
Регрессионный анализ и системы одновременных уравнений |
|
|
Количественная |
Единственная количественная переменная, интерпретируемая как «время» |
Анализ временных рядов |
|
|
Количественная |
Неколичественная (ординальные или номинальные переменные) |
Дисперсионный анализ |
|
|
Количественная |
Ковариационный анализ, модели типологической регрессии |
||
|
Неколичественная (ординальные переменные) |
Неколичественная (ординальные и номинальные переменные) |
Анализ ранговых корреляций и таблиц сопряженности |
|
|
Неколичественная (номинальные переменные) |
Количественная |
Дискриминантный анализ, логит- и пробит-модели, кластер-анализ, таксономия, расщепление смесей распределений |
|
|
Смешанная (количественные и неколичественные переменные) |
Смешанная (количественные и неколичественные переменные) |
Аппарат логических решающих функций, Data Mining |
Тем не менее, практика статистического анализа и прогнозирования в бизнесе
свидетельствует о том, что во всем спектре их математического инструментария
бесспорное лидерство (по распространенности и актуальности) принадлежит трем
разделам:
- регрессионному анализу;
-
анализу временных рядов;
-
механизму формирования и статистического анализа экспертных оценок.
Кратко остановимся на каждом из этих разделов.
Регрессионный анализ
Как и прежде, будем описывать функционирование исследуемого реального объекта (фирмы, компании, процесса производства или дистрибуции продукции и т. п.) набором переменных и (их содержательный смысл описан в п. 2). Введем ряд определений и понятий, используемых в регрессионном анализе.
Результирующие (зависимые, эндогенные) переменные.
Переменная
, характеризующая
результат или эффективность функционирования анализируемой системы, называется
результирующей (зависимой, эндогенной). Ее значения формируются в процессе и
внутри функционирования этой системы под воздействием ряда других переменных
и факторов, часть из которых поддается регистрации и, в определенной степени,
управлению и планированию (эту часть принято называть объясняющими переменными,
см. ниже). В регрессионном анализе результирующая переменная выступает в роли
функции, значения которой определяются (правда, с некоторой случайной погрешностью)
значениями упомянутых выше объясняющих переменных, выступающих в роли аргументов.
Поэтому по природе своей результирующая переменная всегда стохастична
(случайна). В общем случае обычно анализируется поведение сразу нескольких
результирующих
переменных ![]() .
.
Объясняющие (предикторные, экзогенные) переменные
![]() . Переменные
(или признаки), поддающиеся регистрации, описывающие условия функционирования
изучаемой реальной экономической системы и в существенной мере определяющие
процесс формирования значений результирующих переменных, называются объясняющими.
Как правило, часть из них поддается хотя бы частичному регулированию и управлению.
Значения ряда объясняющих переменных могут задаваться как бы «извне» анализируемой
системы. В этом случае их принято называть экзогенными. В регрессионном анализе
они играют роль аргументов той функции, в качестве которой рассматривается анализируемый
результирующий показатель . По своей
природе объясняющие переменные могут быть как случайными, так и неслучайными.
. Переменные
(или признаки), поддающиеся регистрации, описывающие условия функционирования
изучаемой реальной экономической системы и в существенной мере определяющие
процесс формирования значений результирующих переменных, называются объясняющими.
Как правило, часть из них поддается хотя бы частичному регулированию и управлению.
Значения ряда объясняющих переменных могут задаваться как бы «извне» анализируемой
системы. В этом случае их принято называть экзогенными. В регрессионном анализе
они играют роль аргументов той функции, в качестве которой рассматривается анализируемый
результирующий показатель . По своей
природе объясняющие переменные могут быть как случайными, так и неслучайными.
Регрессионные остатки
– это
латентные (т. е. скрытые, не поддающиеся непосредственному измерению) случайные
компоненты, отражающие влияние соответственно на ![]() не учтенных
в составе факторов, а
также случайные ошибки в измерении анализируемых результирующих переменных.
Они, вообще говоря, тоже могут зависеть от , т. е.
в общем случае .
не учтенных
в составе факторов, а
также случайные ошибки в измерении анализируемых результирующих переменных.
Они, вообще говоря, тоже могут зависеть от , т. е.
в общем случае .
Общая схема взаимодействия переменных в регрессионном анализе изображена на рисунке.

Рисунок . Общая схема взаимодействия переменных в регрессионном анализе.
Функция регрессии по . Функция называется функцией регрессии по (или просто – регрессией по ), если она описывает изменение условного среднего значения результирующей переменной (при условии, что значения объясняющих переменных зафиксированы на уровнях ) в зависимости от изменения значений объясняющих переменных. Соответственно математически это определение может быть записано в виде
где символ означает операцию теоретического усреднения значений (т. е. – это математическое ожидание случайной величины , а , или просто – это условное математическое ожидание случайной величины , вычисленное при условии, что значения объясняющих переменных зафиксированы на уровне ).
Если мы анализируем одновременно результирующих переменных , то следует рассмотреть соответственно функций регрессий или, что то же, одну векторнозначную функцию
 . (11)
. (11)
Тогда модель регрессии ![]() по может быть
записана в виде
по может быть
записана в виде
, (12)
причем, из определения следует, что всегда]
![]() (12’)
(12’)
(тождественный знак равенства в (12’) означает, что оно справедливо при любых значениях ; вектор-столбец из нулей в правой части имеет размерность ).
задача регрессионного анализа в самом общем виде может быть сформулирована следующим образом:
по результатам измерений
исследуемых переменных на объектах (системах,
процессах) анализируемой совокупности построить такую (векторнозначную) функцию
(11), которая позволила бы наилучшим (в определенном смысле) образом восстанавливать
значения результирующих (прогнозируемых) переменных ![]() по заданным
значениям объясняющих (экзогенных) переменных .
по заданным
значениям объясняющих (экзогенных) переменных .
З а м е ч а н и е 1. Наиболее распространенными являются линейные модели регрессии, т. е. модели, в которых функции регрессии имеют линейный вид:
З а м е ч а н и е 2. Существует
по меньшей мере два варианта интерпретации введенных в п. 2 «поведенческих»,
«статусных» и «внешних» переменных, соответственно, и в рамках описанной
модели регрессии (12)–(12’). В первом варианте все три типа
переменных
и относят к объясняющим
переменным и строят регрессию по . В другом
варианте переменные и интерпретируют
как условия проведения наблюдений
и тогда отдельно
для каждого
фиксированного сочетания этих условий строят регрессионную модель вида (12)
(в рамках линейной модели (12 ’’) это будет означать, что сами коэффициенты
регрессии ![]() зависят от
и , т. е.
определяются как функции от и ).
зависят от
и , т. е.
определяются как функции от и ).
Анализ временных рядов
Всякий статистический анализ и прогноз основывается на исходных статистических данных. Их основные типы были представлены в п. 1. При этом, если процесс регистрации данных происходит во времени , и само время фиксируется наряду со значениями анализируемых характеристик , то говорят о статистическом анализе так называемых панельных данных . Если зафиксировать номер переменной и номер статистически обследуемого объекта , то расположенную в хронологическом порядке последовательность значений
называют одномерным временным рядом . Если же одновременно рассматривать одномерных временных рядов вида (13), т. е. исследовать закономерности во взаимосвязанном поведении временных рядов (13) для , характеризующих динамику переменных, измеренных на каком-то одном ( -м) объекте , то тогда говорят о статистическом анализе многомерного временного ряда . По существу, все задачи, связанные с анализом экономической динамики и прогнозом, предусматривают использование в качестве своей статистической базы временных рядов тех или иных показателей.
Как правило, в задачах бизнес-прогнозирования рассматриваются лишь дискретные (по времени наблюдения ) одномерные временные ряды для равноотстоящих моментов наблюдения , т. е. где – заданный временной такт (минута, час, сутки, неделя, месяц, квартал, год и т. п.). В этих случаях исследуемый временной ряд нам будет удобнее представлять в виде
где – значение анализируемого показателя, зарегистрированное в -м такте времени .
Говоря об использовании аппарата анализа временных рядов в проблеме прогнозирования, мы имеем в виду кратко - и среднесрочный прогноз , поскольку построение долгосрочного прогноза подразумевает обязательное использование методов организации и статистического анализа специальных экспертных оценок .
Генезис наблюдений, образующих временной ряд . Речь идет о структуре и классификации основных факторов, под воздействием которых формируются значения элементов временного ряда. Целесообразно выделить следующие 4 типа таких факторов.
(А) Долговременные , формирующие общую (в длительной перспективе) тенденцию в изменении анализируемого признака . Обычно эта тенденция описывается с помощью той или иной неслучайной функции f тр (t), как правило, монотонной. Эту функцию называют функцией тренда или просто трендом .
(Б) Сезонные , формирующие периодически повторяющиеся в определенное время года колебания анализируемого признака. Условимся обозначать результат действия сезонных факторов с помощью неслучайной функции . Поскольку эта функция должна быть периодической (с периодами, кратными сезонам, т. е. кварталам), в ее аналитическом выражении участвуют гармоники (тригонометрические функции), периодичность которых, как правило, обусловлена содержательной сущностью задачи.
(В) Циклические (конъюнктурные ), формирующие изменения анализируемого признака, обусловленные действием долговременных циклов экономической, демографической или астрофизической природы (волны Кондратьева, демографические «ямы», циклы солнечной активности и т. п.). Результат действия циклических факторов будем обозначать с помощью неслучайной функции .
(Г) Случайные (нерегулярные), не поддающиеся учету и регистрации. Их воздействие на формирование значений временного ряда как раз и обусловливает стохастическую природу элементов , а следовательно, и необходимость интерпретации как наблюдений, произведенных над случайными величинами соответственно . Будем обозначать результат воздействия случайных факторов с помощью случайных величин («остатков», «ошибок») . Конечно, вовсе не обязательно, чтобы в процессе формирования значений всякого временного ряда участвовали одновременно факторы всех четырех типов. В одних случаях значения временного ряда могут формироваться под воздействием факторов (А), (Б) и (Г), в других – под воздействием факторов (А), (В) и (Г) и, наконец, – исключительно под воздействием одних только случайных факторов (Г). Однако во всех случаях предполагается непременное участие случайных (эволюционных ) факторов (Г). Кроме того, как правило, принимается (в качестве гипотезы) аддитивная структурная схема влияния факторов (А), (Б), (В) и (Г) на формирование значений , которая означает правомерность представления значений членов временного ряда в виде разложения:
Выводы о том, участвуют или нет факторы данного типа в формировании значений , могут базироваться как на анализе содержательной сущности задачи (т. е. быть априорно-экспертными по своей природе ), так и на специальном статистическом анализе исследуемого временного ряда .
В рамках введенных понятий и обозначений задача статистического анализа временного ряда в общем виде может быть сформулирована следующим образом:
по результатам измерений исследуемой переменной за тактов времени базового периода построить наилучшие (в определенном смысле) оценки для членов разложения (14).
Решение этой задачи используется для построения прогнозного значения на тактов времени вперед с помощью формулы (14) при и при подстановке в нее полученных оценок компонентов правой части разложения.
Механизмы формирования и статистический анализ экспертных оценок
Обычно выделяются следующие основные типы организации работы группы экспертов ():
· коллегиальный : «метод комиссий» (в виде открытой дискуссии по обсуждаемой проблеме); «метод суда» (в виде противостояния «защиты» и «обвинения» по каждому из вариантов обсуждаемого решения проблемы); «мозговая атака» и т.п.;
· частично коллегиальный: сценарный анализ типа «что – если», метод «Делфи» – многотуровое обсуждение проблемы с тайным голосованием экспертов или заполнением специальных анонимных анкет в конце каждого тура и работой независимой аналитической группы в промежутках между турами и т.п.;
· индивидуально-автономный: каждый из участников экспертной группы формирует и высказывает свое мнение (независимо от позиций других участников) в виде ранжирования обсуждаемых вариантов решения (или объектов), их парных сравнений или отнесения каждого из них к одной из заранее описанных градаций (см. формы представления исходных статистических данных в виде таблиц частот или таблиц сопряженности в между мнениями -го и -го экспертов измеряют величиной , где – коэффициент ранговой корреляции Спирмена (см. , гл. 11]). Определив тот или иной способ вычисления «расстояния» между мнениями пары экспертов, мы можем решать затем задачу «кластеризации» экспертов, интерпретируя каждый из найденных таким образом кластер как группу экспертов-единомышленников.
(ii) Анализ взаимной согласованности мнений группы экспертов. Располагая мнениями целой группы экспертов, аналитик-статистик стремится оценить степень согласованности всех этих экспертных оценок, в том числе и статистически проверить гипотезу о полном отсутствии какой-либо их согласованности (и тогда, очевидно, следует либо уточнить постановку предложенной экспертам задачи, либо поменять состав экспертной группы). Эта задача также решается средствами многомерного статистического анализа. Выбор конкретного метода зависит от формы исходных статистических данных. Например, если мнения экспертов представлены ранжировками, то в качестве меры их согласованности можно рассматривать коэффициент объектов), т.е. при исходных статистических данных вида определяется как решение оптимизационной задачи видаj -го эксперта отстоит от единого группового мнения, тем ниже оценивается уровень его относительной компетентности. Заметим, что если в результате исследования структуры совокупности экспертных мнений аналитик-статистик приходит к выводу о наличии нескольких подгрупп экспертов с однородностью мнений внутри каждой подгруппы и с существенным различием мнений в любой паре таких подгрупп, то задача единого группового мнения и оценка относительной компетентности эксперта решается отдельно для каждой из выявленных подгрупп.
Случайные факторы, в свою очередь, могут быть двоякой природы: внезапными («разладочными»), приводящими к скачкообразным структурным изменениям в механизме формирования значений x(t) (что выражается, например, в радикальных скачкообразных изменениях основных структурных характеристик функций f тр (t), j (t) и y (t) анализируемого временного ряда в случайный момент времени), и эволюционными остаточными , обусловливающими относительно небольшие случайные отклонения значений x(t) от тех, которые должны были бы получиться только под воздействием факторов (А), (Б) и (В). Однако в данном разделе будут рассмотрены схемы формирования временных рядов, включающие в себя действие только эволюционных остаточных случайных факторов.
| Предыдущая |
Статистические наблюдения в социально-экономических исследованиях обычно проводятся регулярно через равные отрезки времени и представляются в виде временных рядов x t , где t = 1, 2, ..., п. В качестве инструмента статистического прогнозирования временных рядов служат трендовые регрессионные модели, параметры которых оцениваются по имеющейся статистической базе, а затем основные тенденции (тренды) экстраполируются на заданный интервал времени.
Методология статистического прогнозирования предполагает построение и испытание многих моделей для каждого временного ряда,ихсравнение на основе статистических критериев и отбор наилучшихизних для прогнозирования.
При моделировании сезонных явлений в статистических исследованиях различают два типа колебаний: мультипликативные и аддитивные. В мультипликативном случае размах сезонных колебаний изменяется во времени пропорционально уровню тренда и отражается в статистической модели множителем. При аддитивной сезонности предполагается, что амплитуда сезонных отклонений постоянна и не зависит от уровня тренда, а сами колебания представлены в модели слагаемым.
Основой большинства методов прогнозирования является экстраполяция, связанная с распространением закономерностей, связей и соотношений, действующих в изучаемом периоде, за его пределы, или - в более широком смысле слова - это получение представлений о будущем на основе информации, относящейся к прошлому и настоящему.
Наиболее известны и широко применяются трендовые и адаптивные методы прогнозирования. Среди последних можно выделить такие, как методы авторегрессии, скользящего среднего (Бокса - Дженкинса и адаптивной фильтрации), методы экспоненциального сглаживания (Хольта, Брауна и экспоненциальной средней) и др.
Для оценки качества исследуемой модели прогноза используют несколько статистических критериев.
Наиболее распространенными критериями являются следующие.
Относительная ошибка аппроксимации:
где e t = х t - - ошибка прогноза;
х t - фактическое значение показателя;
- прогнозируемое значение.
Данный показатель используется в случае сравнения точности прогнозов по нескольким моделям. При этом считают, что точность модели является высокой, когда < 10%, хорошей - при = 10-20% и удовлетворительной - при = 20-50%.
Средняя квадратическая ошибка:
 (54.2)
(54.2)
где k - число оцениваемых коэффициентов уравнения.
Наряду с точечным в практике прогнозирования широко используют интервальный прогноз. При этом доверительный интервал чаще всего задается неравенствами
![]() (54.3)
(54.3)
где t α - табличное значение, определяемое по t -распределению Стьюдента при уровне значимости α и числе степеней свободы п - k.
В литературе представлено большое число математико-статистических моделей для адекватного описания разнообразных тенденций временных рядов.
Наиболее распространенными видами трендовых моделей, характеризующих монотонное возрастание или убывание исследуемого явления, являются:
 (54.4)
(54.4)
Правильно выбранная модель должна соответствовать характеру изменений тенденции исследуемого явления; При этом величина е t должна носить случайный характер с нулевой средней.
Кроме того, ошибки аппроксимации e t должны быть независимыми между собой и подчиняться нормальному закону распределения e t Î N (0, σ ). Независимость ошибок e t , т.е. отсутствие автокорреляции остатков, обычно проверяется по критерию Дарбина-Уотсона, основанного на статистике:
 (54.5)
(54.5)
где e t = x t - .
Если отклонения не коррелированы, то величина DW приблизительно равна двум. При наличии положительной автокорреляции 0 ≤ DW ≤ 2, а отрицательной - 2 ≤ D W ≤ 4.
О коррелированности остатков можно также судить по коррелограмме для отклонений от тренда, которая представляет собой график функции относительно τ коэффициента автокорреляции, который вычисляется по формуле
 (54.6)
(54.6)
где τ = 0, 1, 2 ... .
После выбора наиболее подходящей аналитической функции для тренда его используют для прогнозирования на основе экстраполяции на заданное число временных интервалов.
Рассмотрим задачу сглаживания сезонных колебаний, исходя из ряда V t = х t - , где x t - значение исходного временного ряда в момент t, а - оценка соответствующего значения тренда (t = 1, 2, ..., п ).
Так как сезонные колебания представляют собой циклический, повторяющийся во времени процесс, то в качестве сглаживающих функций используется гармонический ряд (ряд Фурье) следующего вида:

Оценки параметров α i и β i модели определяют из выражений
 (54.7)
(54.7)
где k = п / 2 - максимально допустимое число гармоник;
ω i = 2πi / п - угловая частота i -й гармоники (i = 1, 2, ..., т).
Пусть т - число гармоник, используемых для сглаживания сезонных колебаний (т < k). Тогда оценка гармонического ряда имеетвид
 (54.8)
(54.8)
а расчетные значения временного ряда исходного показателя определяются по формуле
![]()
54.2. Адаптивные методы прогнозирования
При использовании трендовых моделей в прогнозировании обычно предполагается, что основные факторы и тенденции прошлого периода сохранятся на период прогноза или что можно обосновать и учесть направление их изменений в перспективе. Однако в настоящее время, когда происходит структурная перестройка экономики, социально-экономические процессы даже на макроуровне становятся очень динамичными. В этой связи исследователь часто имеет дело с новыми явлениями и с короткими временными рядами. При этом устаревшие данные при моделировании часто оказываются бесполезными и даже вредными. Таким образом, возникает необходимость строить модели, опираясь в основном на малое количество самых свежих данных, наделяя модели адаптивными свойствами.
Важную роль в деле совершенствования прогнозирования должны сыграть адаптивные методы, цель которых заключается в построении самонастраивающихся моделей, которые способны учитывать информационную ценность различных членов временного ряда и давать достаточно точные оценки будущих членов данного ряда. Адаптивные модели достаточно гибки, однако на их универсальность, пригодность для любого временного ряда рассчитывать не приходится.
При построении конкретных моделей необходимо учитывать наиболее вероятные закономерности развития реального процесса. Исследователь должен закладывать в модель те адаптивные свойства, которых достаточно для слежения за реальным процессом с заданной точностью.
У истоков адаптивного направления лежит простейшая модель экспоненциального сглаживания, обобщение которой привело в появлению целого семейства адаптивных моделей. Простейшая адаптивная модель основывается на вычислении экспоненциально взвешенной скользящей средней.
Экспоненциальное сглаживание исходного временного ряда x t осуществляется по рекуррентной формуле
![]() (54.9)
(54.9)
где S t - значение экспоненциальной средней в момент t, a. S t-1 - в момент t -1;
α - параметр сглаживания, адаптации, α = const, 0 < α < 1;
Выражение (54.9) можно представить в виде
В (54.10) экспоненциальная средняя в момент t выражена как экспоненциальная средняя предшествующего момента S t-1 плюс доля α отклонения текущего наблюдения х t от экспоненциальной средней S t-1 момента t - 1.
Последовательно используя рекуррентное соотношение (54.9), можно выразить экспоненциальную среднюю S t через значения временного ряда:
где S 0 - величина, характеризующая начальные условия для первого применения формулы (54.9), при t = 1.
Так как β = (1 - α) < 1, то при t → 0 β t → 0, и, согласно (54.11),
 (54.12)
(54.12)
т.е. величина S t оказывается взвешенной суммой всех членов ряда. При этом веса падают экспоненциально в зависимости от давности наблюдения, откуда и название S t - экспоненциальная средняя.
Из (54.12) следует, что увеличение веса более свежих наблюдений может быть достигнуто повышением α. В то же время для сглаживания случайных колебаний временного ряда x t величину α нужно уменьшить. Два названных требования находятся в противоречии, и на практике при выборе α исходят из компромиссного решения.
Экспоненциальное сглаживание является простейшим видом самообучающейся модели с параметром адаптации α. Разработано несколько вариантов адаптивных моделей, которые используют процедуру экспоненциального сглаживания и позволяют учесть наличие у временного ряда x t тенденции и сезонных колебаний. Рассмотрим некоторыеизтаких моделей.
Адаптивная полиномиальная модель первого порядка
Рассмотрим алгоритм экспоненциального сглаживания, предполагающий наличие у временного ряда x t линейного тренда. В основе модели лежит гипотеза о том, что прогноз может быть получен по уравнению
![]()
где - прогнозируемое значение временного ряда на момент (t + τ);
, - оценки адаптивных коэффициентов полинома первого порядка в момент t;
τ - величина упреждения.
Экспоненциальные средние 1-го и 2-го порядков для модели имеют вид
 (54.13)
(54.13)
где β = 1 - α, а оценка модельного значения ряда с периодом упреждения τ равна
 (54.14)
(54.14)
Для определения начальных условий первоначально по данным временного ряда x t находим методом наименьших квадратов оценки линейного тренда:
![]()
и принимаем и . Тогда начальные условия определяются как:
 (54.15)
(54.15)
Контрольные вопросы
1. Какие модели прогнозирования вы знаете и каковы их особенности?
2. В чем состоит статистический подход к прогнозированию, моделированию тенденций и сезонных явлений в стратегических исследованиях?
3. Какие трендовые модели вам известны и как оценивается их качество?
4. В чем особенность адаптивных методов прогнозирования?
5. Какимобразом осуществляется экспоненциальное сглаживание временного ряда?