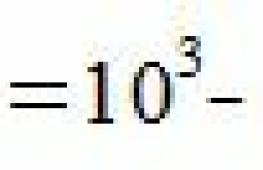Методы аппроксимации функций. Метод аппроксимации в Microsoft Excel
В предыдущих разделах был рассмотрен один из способов приближения функции к табличным данным - интерполяция. Отличительной особенностью ее являлось то, что интерполирующая функция строго проходила через узловые точки таблицы, т. е. рассчитанные значения совпадали с табличными - у,=/(х,). Эта особенность обусловливалась тем, что количество коэффициентов в интерполирующей функции (/и) было равно количеству табличных значений (л). Однако, если для описания табличных данных будет выбрана функция с меньшим количеством коэффициентов (т), что часто встречается на практике, то уже нельзя подобрать коэффициенты функции так, чтобы функция проходила через каждую узловую точку. В лучшем случае она будет проходить каким-либо образом между ними и очень близко к ним (рис. 5.4). Такой способ описания табличных данных называется аппроксимацией, а функция - аппроксимирующей.
Рис. 5.4
- --интерполирующая функция;
- -----аппроксимирующая функция
Казалось бы, с помощью метода интерполяции можно описать табличные данные более точно, чем аппроксимации, тем не менее на практике возникают ситуации, когда последний метод предпочтительнее. Перечислим эти ситуации.
- 1. Когда количество табличных значений очень велико. В этом случае интерполирующая функция будет очень громоздкой. Удобнее выбрать более простую в применении функцию с небольшим количеством коэффициентов, хотя и менее точную.
- 2. Когда вид функции заранее определен. Такая ситуация возникает, если требуется описать экспериментальные точки какой-либо теоретической зависимостью. Например, константа скорости химической реакции зависит от температуры по уравнению Аррениуса к=кц - елр(-E/RT), в котором два определяемых параметра к 0 - предэкспоненциальный множитель, Е - энергия активации. А так как почти всегда экспериментальных точек бывает больше двух, то и возникает необходимость в аппроксимации.
- 3. Аппроксимирующая функция может сглаживать погрешности эксперимента, в отличие от интерполирующей функции. Так, на рис. 5.5 точками показаны табличные данные - результат некоторого эксперимента. Очевидно, что Y монотонно возрастает с увеличением X, а разброс данных объясняется погрешностью эксперимента.

Рис. 5.5
Однако интерполирующая функция, проходя через каждую точку, будет повторять ошибки эксперимента, иметь множество экстремумов - минимумов и максимумов - и в целом неверно отображать характер зависимости У от X. Этого недостатка лишена аппроксимирующая функция.
4. И наконец, интерполирующей функцией невозможно описать табличные данные, в которых есть несколько точек с одинаковым значением аргумента. А такая ситуация возможна, если один и тот же эксперимент проводится несколько раз при одних и тех же исходных данных.
Постановка задачи. Пусть, изучая неизвестную функциональную зависимость y=J{x), был произведен ряд измерений величин х и у.
Если аналитическое выражение функции Дх) неизвестно или весьма сложно, то возникает практически важная задача: найти такую эмпирическую формулу
значения которой при х=х, возможно мало отличались бы от опытных данных у, (/ = 1,2, ..., п).
Как правило, указывают достаточно узкий класс функций К (например, множество функций линейных, степенных, показательных и т. п.), которому должна принадлежать искомая функция /(х). Таким образом, задача сводится к нахождению наилучших значений параметров.
Геометрически задача построения эмпирической формулы состоит в проведении кривой Г, «возможно ближе» примыкающей к системе точек (рис. 5.6) Mi(Xi,y,) (/=1,2, ..., л).

Рис. 5.6
Следует отметить, что задача построения эмпирической формулы отлична от задачи интерполирования. Известно, что эмпирические данные х, и y h как правило, приближенные и содержат ошибки. Поэтому интерполяционная формула повторяет эти ошибки и не является идеальным решением поставленной задачи. Весьма вероятно, что более простая эмпирическая зависимость будет сглаживать данные и не будет повторять ошибки, как в случае интерполирования. График эмпирической зависимости не проходит через заданные точки, как это имеет место в случае интерполяции.
Построение эмпирической зависимости слагается из двух этапов:
- выяснение общего вида формулы;
- определение наилучших параметров эмпирической зависимости.
Если неизвестен характер зависимости между данными величинами х и у, то вид эмпирической формулы является произвольным. Предпочтение отдается простым формулам, обладающим хорошей точностью. Если отсутствуют сведения о промежуточных данных, то обычно предполагается, что эмпирическая функция аналитическая, без точек разрыва, и график ее - плавная кривая.
Удачный подбор эмпирической формулы в значительной мере зависит от опыта и искусства составителя. Во многих случаях задача состоит в аппроксимации неизвестной функциональной зависимости между х и у многочленом заданной степени т

Нередко употребляются другие элементарные функции (дробно- линейная, степенная, показательная, логарифмическая и т. п.). Что касается определения наилучших значений параметров, входящих в эмпирическую формулу, то эта задача более легкая и решается регулярными методами. Наиболее часто применяемым методом определения параметров эмпирической формулы является метод наименьших квадратов.
Иногда возникает необходимость аппроксимации данной функции другими функциям, которые легче вычислить. В частности, рассматривается задача о наилучшем приближении в нормированном пространстве Н, когда заданную функцию f требуется заменить линейной комбинацией заданных элементов из Н так, чтобы отклонение ||f - || было минимальным.
Метод наименьших квадратов
Mетод наименьших квадратов был предложен Гауссом и Лежандром в конце XVIII - начале XIX веков в связи с проблемой обработки экспериментальных данных. В этом случае задача построения функции непрерывного аргумента по дискретной информации, характеризуется двумя особенностями:
- 1. Число точек, в которых проводятся измерения, обычно бывает достаточно большим.
- 2. Значения функции в точках сетки определяются приближенно в связи с неизбежными ошибками измерения.
С учетом этих обстоятельств строить функцию в виде суммы большого числа слагаемых и добиваться ее точного равенства в точках сетки величинам, как это делалось при интерполировании, становится нецелесообразным.
В методе наименьших квадратов аппроксимирующая функция ищется в виде суммы, аналогичной, но содержащей сравнительно небольшое число слагаемых
погрешность уравнение интерполяция
в частности, возможен вариант.
Предположим, что мы каким-то образом выбрали коэффициенты, тогда в каждой точке сетки, можно подсчитать погрешность
Сумма квадратов этих величин называется суммарной квадратичной погрешностью

Она дает количественную оценку того, насколько близки значения функции в точках сетки к величинам.
Меняя значения коэффициентов, мы будем менять погрешность, которая является их функцией. В результате естественно возникает задача:
Найти такой, набор коэффициентов, при которых суммарная квадратичная погрешность оказывается минимальной.
Функцию с набором коэффициентов, удовлетворяющих этому требованию, называют наилучшим приближением по методу наименьших квадратов.
Построение наилучшего приближения сводится к классической задаче математического анализа об экстремуме функции нескольких переменных. Метод решения этой задачи известен.
Необходимым условием экстремума является равенство нулю в экстремальном точке всех первых частных производных рассматриваемой функции. В случае это дает
Оставим члены, содержащие, слева и поменяем в них порядок суммирования по индексам и. Члены, содержащие, перенесем направо. В результате уравнения примут вид



Мы получили систему линейных алгебраических уравнений, в которой роль неизвестных играют искомые коэффициенты разложения. Число уравнении и число неизвестных в этой системе совпадает и равно. Матрица коэффициентов системы Г состоит из элементов, которые определяются формулой. Ее называют матрицей Грама для системы функций на сетке. Отметим, что матрица Грама является симметричной: для ее элементов, согласно, справедливо равенство. Числа, стоящие в правой части уравнений, вычисляются по формуле через значения сеточной функции.
Предположим, что функции выбраны такими, что определитель матрицы Грама, отличен от нуля:
В этом случае при любой правой части система имеет единственное решение

Рассмотрим наряду с набором коэффициентов, полученных в результате решения системы, любой другой набор коэффициентов. Представим числа в виде
и сравним значения суммарной квадратичной погрешности для функций, построенных с помощью коэффициентов и.

Квадрат погрешности и точке для функции с коэффициентами можно записать в виде
Здесь в среднем слагаемом мы заменили в одной из сумм индекс суммирования на, чтобы не использовать один и тот же индекс в двух разных суммах и иметь возможность перемножить их почленно.
Чтобы получить суммарную квадратичную погрешность, нужно просуммировать выражения для по индексу Первые слагаемые не содержат. Их сумма дает погрешность, вычисленную для функции с коэффициентами.

Рассмотрим теперь сумму вторых слагаемых, которые зависят от линейно:
Здесь мы поменяли местами порядок суммирования и воспользовались тем, что коэффициенты, удовлетворяют системе уравнений.

С учетом будем иметь
Формула показывает, что функция с коэффициентами, полученными в результате решения уравнений, действительно минимизирует суммарную квадратичную погрешность. Если мы возьмем любой другой набор коэффициентов, отличный от, то согласно формуле к погрешности добавится положительное слагаемое и она увеличится.
Итак, чтобы построить наилучшее приближение сеточной функции, по методу наименьших квадратов, нужно взять в качестве коэффициентов разложения решение системы линейных уравнений.
 Зачем нужна аппроксимация функций В окружающем нас мире все взаимосвя-зано, поэтому одной из наиболее часто встре-чающихся задач является поиск зависимости между различными величинами, что позволяет по значению одной величины определить значение другой. Математической моделью такой зависимости является понятие функции y = f (x).
Зачем нужна аппроксимация функций В окружающем нас мире все взаимосвя-зано, поэтому одной из наиболее часто встре-чающихся задач является поиск зависимости между различными величинами, что позволяет по значению одной величины определить значение другой. Математической моделью такой зависимости является понятие функции y = f (x).
 При расчетах, связанных с обработкой полученных экспериментальных данных, вычислением f (x), разработкой вычислительных методов, встречаются следующие две ситуации: 1. Как установить вид функции y = f (x), если она неизвестна, а известны только некоторые ее значения (полученные из экспериментальных измерений, или из сложных расчетов). 2. Как упростить вычисление известной функции f (x) или ее характеристик, если f (x) имеет слишком сложный вид?
При расчетах, связанных с обработкой полученных экспериментальных данных, вычислением f (x), разработкой вычислительных методов, встречаются следующие две ситуации: 1. Как установить вид функции y = f (x), если она неизвестна, а известны только некоторые ее значения (полученные из экспериментальных измерений, или из сложных расчетов). 2. Как упростить вычисление известной функции f (x) или ее характеристик, если f (x) имеет слишком сложный вид?
 Ответы на эти вопросы дает теория аппроксимации функций, основная задача которой – нахождение функции (x), близкой (аппроксимирующей) к исходной f (x). ыбирают Функцию (x) чтобы такой, она была максимально удобной для расчетов. Основной подход к решению этой задачи заключается в том, что (x) выбирается зависящей от нескольких свободных параметров, значения которых подбираются из некоторого условия близости функций f (x) и (x).
Ответы на эти вопросы дает теория аппроксимации функций, основная задача которой – нахождение функции (x), близкой (аппроксимирующей) к исходной f (x). ыбирают Функцию (x) чтобы такой, она была максимально удобной для расчетов. Основной подход к решению этой задачи заключается в том, что (x) выбирается зависящей от нескольких свободных параметров, значения которых подбираются из некоторого условия близости функций f (x) и (x).
 Обоснование способа нахождения вида функциональной зависимости и выбора параметров составляет задачу теории аппроксимации функций. В зависимости от способа выбора параметров получены разные методы аппроксимации. Наиболее распространенными являются: интерполяция и среднеквадратичное приближение, частным случаем которого является метод наименьших квадратов.
Обоснование способа нахождения вида функциональной зависимости и выбора параметров составляет задачу теории аппроксимации функций. В зависимости от способа выбора параметров получены разные методы аппроксимации. Наиболее распространенными являются: интерполяция и среднеквадратичное приближение, частным случаем которого является метод наименьших квадратов.
 Наиболее простой является линейная аппроксимация, при которой выбирают функцию линейно зависящую от параметров ci (i = 1, 2, …, n) в виде многочлена: , (1) {φk (x) } – линейно независимые функции, в качестве которых выбирают элементарные функции (тригонометрические, экспоненты, логарифмические или их комбинации).
Наиболее простой является линейная аппроксимация, при которой выбирают функцию линейно зависящую от параметров ci (i = 1, 2, …, n) в виде многочлена: , (1) {φk (x) } – линейно независимые функции, в качестве которых выбирают элементарные функции (тригонометрические, экспоненты, логарифмические или их комбинации).
 Интерполяция это один из способов аппроксимации функций. Суть ее в следующем. Для x на интервале , где функции f и должны быть близки, выбирают систему точек (узлов) x 1
Интерполяция это один из способов аппроксимации функций. Суть ее в следующем. Для x на интервале , где функции f и должны быть близки, выбирают систему точек (узлов) x 1

 В случае линейной аппроксимации (1) система для нахождения коэффициентов сi линейна и имеет следующий вид: (2) При интерполяции для расчетов наиболее удобны обычные алгебраические многочлены.
В случае линейной аппроксимации (1) система для нахождения коэффициентов сi линейна и имеет следующий вид: (2) При интерполяции для расчетов наиболее удобны обычные алгебраические многочлены.
 Интерполяционным многочленом называют алгебраический многочлен степени (n – 1), совпадающий с аппроксимируемой функцией в выбранных n точках (узлах). Общий вид алгебраического многочлена: (3)
Интерполяционным многочленом называют алгебраический многочлен степени (n – 1), совпадающий с аппроксимируемой функцией в выбранных n точках (узлах). Общий вид алгебраического многочлена: (3)
 Матрица системы (2) в этом случае имеет вид. (4) Ее определитель отличен от нуля, если точки xi разные. Поэтому задача (2) обязательно имеет решение.
Матрица системы (2) в этом случае имеет вид. (4) Ее определитель отличен от нуля, если точки xi разные. Поэтому задача (2) обязательно имеет решение.
 При h 0 порядок погрешности интерполяции алгебраическим многочленом равен количеству выбранных узлов n. Величина может быть сделана малой как за счет увеличения n, так и уменьшения h. В практических расчетах обычно используют многочлены невысокого порядка (n 6), в связи с тем, что с ростом n возрастает погрешность вычисления самого многочлена из-за погрешностей округления.
При h 0 порядок погрешности интерполяции алгебраическим многочленом равен количеству выбранных узлов n. Величина может быть сделана малой как за счет увеличения n, так и уменьшения h. В практических расчетах обычно используют многочлены невысокого порядка (n 6), в связи с тем, что с ростом n возрастает погрешность вычисления самого многочлена из-за погрешностей округления.
 Многочлены можно записать по-разному: P 1(x) = 1 – 2 x + x 2 = (x – 1)2. В зависимости от решаемых задач применяют различные виды представления многочлена и способы интерполяции. Наиболее часто используют интерполяционные многочлены Лагранжа и Ньютона. Их особенность в том, что не надо находить параметры сi , т. к. эти многочлены записаны через значения таблицы (узлы) { (xi, yi), i = 1, …, n }.
Многочлены можно записать по-разному: P 1(x) = 1 – 2 x + x 2 = (x – 1)2. В зависимости от решаемых задач применяют различные виды представления многочлена и способы интерполяции. Наиболее часто используют интерполяционные многочлены Лагранжа и Ньютона. Их особенность в том, что не надо находить параметры сi , т. к. эти многочлены записаны через значения таблицы (узлы) { (xi, yi), i = 1, …, n }.



 Параметрами этой функции являются: xt – текущая точка, в которой находится неизвестное значение функции по известным узлам; x и y – узлы, т. е. массивы известных значений (рекомендуется передавать по адресу); m – количество узлов (размер массивов x и y); Понятно, что циклы должны быть организованы от 0 и до значения, меньшего указанного, например первый цикл: for (i = 0; i
Параметрами этой функции являются: xt – текущая точка, в которой находится неизвестное значение функции по известным узлам; x и y – узлы, т. е. массивы известных значений (рекомендуется передавать по адресу); m – количество узлов (размер массивов x и y); Понятно, что циклы должны быть организованы от 0 и до значения, меньшего указанного, например первый цикл: for (i = 0; i
Src="https://present5.com/presentation/91940964_324663347/image-18.jpg" alt="Линейная и квадратичная интерполяция При интерполяции по заданной таблице (узлам) из m > 3"> Линейная и квадратичная интерполяция При интерполяции по заданной таблице (узлам) из m > 3 точек применяют квадратичную для n = 3 или линейную для n = 2 интерполяцию. В этом случае для приближенного вычисления значения функции f в точке x находят в таблице ближайший к этой точке i-й узел, строят интерполяционный многочлен Ньютона первой или второй степени по следующим формулам.
 (1) где xi– 1 ≤ x. Т ≤ xi. За приближенное значение функции f (x. T) принимают N 1(x. T) – линейная интерполяция.
(1) где xi– 1 ≤ x. Т ≤ xi. За приближенное значение функции f (x. T) принимают N 1(x. T) – линейная интерполяция.

 (2) где xi– 1 ≤ x. Т ≤ xi+1. За приближенное значение функции f (xt) принимают N 2(xt) – квадратичная интерполяция.
(2) где xi– 1 ≤ x. Т ≤ xi+1. За приближенное значение функции f (xt) принимают N 2(xt) – квадратичная интерполяция.

 Параметрами функций в рассмотренных схемах линейной и квадратичной интерполяций являются значения, аналогичные рассмотренным в схеме функции расчета многочлена Ньютона. Результат линейной интерполяции yt = N 1(xt) (приближенное значение функции в точке xt) рассчитывается по формуле (1) и возвращается в точку вызова функции, а результат квадратичной интерполяции yt = N 2(xt) – по формуле (2).
Параметрами функций в рассмотренных схемах линейной и квадратичной интерполяций являются значения, аналогичные рассмотренным в схеме функции расчета многочлена Ньютона. Результат линейной интерполяции yt = N 1(xt) (приближенное значение функции в точке xt) рассчитывается по формуле (1) и возвращается в точку вызова функции, а результат квадратичной интерполяции yt = N 2(xt) – по формуле (2).
 Интерполяционный многочлен Лагранжа (8) Многочлены выбраны так, что во всех узлах, кроме k-го, они равны нулю, а в k-м узле – единице: Из выражения (8) видно, что Ln– 1(xi) = yi.
Интерполяционный многочлен Лагранжа (8) Многочлены выбраны так, что во всех узлах, кроме k-го, они равны нулю, а в k-м узле – единице: Из выражения (8) видно, что Ln– 1(xi) = yi.

 Параметрами функции являются значения, аналогичные рассмотренным ранее схемам. Рассчитанный согласно формуле (8) результат yt возвращается в точку вызова функции. Текст функции, реализующий предложенный алгоритм, может иметь следующий вид:
Параметрами функции являются значения, аналогичные рассмотренным ранее схемам. Рассчитанный согласно формуле (8) результат yt возвращается в точку вызова функции. Текст функции, реализующий предложенный алгоритм, может иметь следующий вид:
 double Metod (double xt, double *x, int m) { int i, k; double e, yt = 0; for (k = 0; k
double Metod (double xt, double *x, int m) { int i, k; double e, yt = 0; for (k = 0; k
 В данном случае массив табличных значений функции y не используется, т. к. функция f (x) реализована в виде функции пользователя: double fun (double x) { return «Вид функции f (x)» ; } Вместо блока yt = yt + e yk в схеме алгоритма используем вычисление yt += e * fun (x[k]);
В данном случае массив табличных значений функции y не используется, т. к. функция f (x) реализована в виде функции пользователя: double fun (double x) { return «Вид функции f (x)» ; } Вместо блока yt = yt + e yk в схеме алгоритма используем вычисление yt += e * fun (x[k]);
 Общий алгоритм аппроксимации функции В заданиях вид функции f (x) известен для того, чтобы можно было найти нужное количество узлов (значений таблицы) на отрезке и сравнить полученные результаты. Пусть на отрезке задана таблица из m известных узлов. Необходимо аппроксимировать f (x) в n точках, n ≥ m, т. е. найти по небольшому количеству известных значений m нужное количество n неизвестных значений функции.
Общий алгоритм аппроксимации функции В заданиях вид функции f (x) известен для того, чтобы можно было найти нужное количество узлов (значений таблицы) на отрезке и сравнить полученные результаты. Пусть на отрезке задана таблица из m известных узлов. Необходимо аппроксимировать f (x) в n точках, n ≥ m, т. е. найти по небольшому количеству известных значений m нужное количество n неизвестных значений функции.

"Что такое аппроксимация?" – один из нередко задаваемых в сети интернет вопросов. Жаждущие получить ответ, обычно хотят его иметь в форме: точной, всеобъемлющей и короткой. О содержательности ответа как-то забывают.
Если спросить: "Что такое музыка?", то я, как дилетант, скажу, что музыка – это то, что приятно слушать. А профессионал возможно будет поставлен в тупик таким "простым" вопросом. Однако, ближе к теме.
Аппроксимация – это приближение. Приближение чего-то к чему-то с той или иной точностью. Более пространно: аппроксимация, как процесс, – это построение объекта, с той или иной точностью воспроизводящего те или иные свойства исходного, т.е. аппроксимируемого, объекта. Причем, построение объекта в том или ином отношении более удобного, чем исходный объект.
У аппроксимации может быть множество направлений и приложений. Я могу кратко рассказать о той аппроксимации, которой занимался десятки лет. Более всего, это относилось к процессам топливоиспользования на ТЭС. Десятки, а порой и сотни, разных графиков и таблиц, характеризующих работу энергетического оборудования, приходилось переводить в форму аппроксимирующих уравнений или формул. То есть, одни математические объекты – графики и таблицы – воспроизводились другими математическими объектами – аппроксимирующими формулами. После чего формулы заводились на ЭВМ или персональный компьютер, и по ним можно было получить все нужные выходные данные, не водя пальцем по исходным графикам или делая какие-то грубые оценки по таблицам.
Кроме этого, мне, как программисту (или алгоритмисту), приходилось создавать довольно сложные программы – модели, описывающие технологический процесс. Порой эти программы были весьма неудобны для обычного пользователя. Но полученные расчетным путем данные вполне удавалось воспроизвести достаточно точной и простой в обращении аппроксимирующей формулой.
Вы можете в Excel построить график и щелкнуть по нему правой кнопкой мыши. Появится запрос: Вставить линию тренда. Там же можно будет разместить на графике и уравнение тренда. Это и будет примером аппроксимирующей формулы. На нашем сайте вы также можете найти десятки примеров аппроксимации.
Но чтобы получить более или менее содержательное представление, скажем, о пилке дров, надо сначала обрести хотя бы какие-то навыки владения пилой. Тоже самое и с аппроксимацией.
P.S. Решил посмотреть как интерпретируется слово "аппроксимация" в сети интернет. Более других мне понравилась интерпретация в Большом Энциклопедическом Словаре (БЭС):
"АППРОКСИМАЦИЯ (от лат. approximo - приближаюсь), замена одних математических объектов (напр., чисел или функций) другими, более простыми и в том или ином смысле близкими к исходным (напр., кривых линий близкими к ним ломаными)".
Только "замена" – это, в моем понимании, нечто вторичное. А первичное – "приближение". Я, например, порой строил десятки аппроксимирующих формул, добиваясь наилучшего приближения к исходной таблице данных. А собственно "замена" в основном касалась замены одной аппроксимирующей формулы на другую, более удачную. Впрочем, пользователь уже мог использовать мою аппроксимирующую формулы "взамен" исходной таблицы.
В Большой Советской Энциклопедии (БСЭ) находим более развернутое определение:
"Аппроксимация (от лат. approximo - приближаюсь), замена одних математических объектов другими, в том или ином смысле близкими к исходным. Аппроксимация позволяет исследовать числовые характеристики и качественные свойства объекта, сводя задачу к изучению более простых или более удобных объектов (например, таких, характеристики которых легко вычисляются или свойства которых уже известны). В теории чисел изучаются диофантовы приближения, в частности приближения иррациональных чисел рациональными. В геометрии и топологии рассматриваются аппроксимации кривых, поверхностей, пространств и отображений. Некоторые разделы математики целиком посвящены аппроксимации; например, приближение и интерполирование функций, численные методы анализа. Роль аппроксимации в математике непрерывно возрастает. В настоящее время аппроксимация может рассматриваться как одно из основных понятий математики". С. Б. Стечкин.
Осталось только поинтересоваться что означают "диофантовы приближения" и прочие специальные термины и все станет окончательно понятно.
В Википедии (свободной энциклопедии) очень короткое определение:
"Аппроксимация, или приближение - научный метод, состоящий в замене одних объектов другими, в том или ином смысле близкими к исходным, но более простыми".
Позволю себе заметить, что "приближение" – это не есть "замена" или это "замена" в каком-то очень узком и специальном смысле, например в смысле "использование вместо".
В словаре бизнес-терминов находим весьма расплывчатое, на мой взгляд, определение:
"Аппроксимация – приближенное решение сложной функции с помощью более простых, что резко ускоряет и упрощает решение задач. В экономике целью аппроксимации часто является укрупнение характеристик моделируемых экономических объектов".
В философской энциклопедии:
"АППРОКСИМАЦИЯ (от лат. approximare - приближаться) - метод сознательного упрощения "слишком точного" теоретического знания с целью привести его в соответствие с потребностями и возможностями практики. Например, использование числа "пи" с точностью до пятого знака после запятой достаточно для решения поставленной практической задачи. Аппроксимация первоначально использовалась в математике и затем распространилась на все науки. Аппроксимация противоположна идеализации". Г. Д. Левин.
В научной диалектике есть положение: "Истина всегда конкретна". Так и с аппроксимацией – нет аппроксимации "вообще". Ее содержательная часть – в конкретных приложениях и в конкретных областях. Я, например, занимался аппроксимацией графиков и табличных данных посредством подбора подходящих для этого формул с использованием метода наименьших квадратов, встроенного в электронные таблицы Quattro Pro и Excel. А способов подбора – десятки, и это уже не только наука, но и искусство. Ваш, Протасов Н.Г.
P.P.S. Вот еще информация, дополняющая в достаточно простой и понятной форме тему аппроксимации. Эта информация находится по адресу http://univer-nn.ru/ , а здесь я привожу ее в несколько сокращенном виде:
Задача аппроксимации (задача о приближении)
Пусть y = f(x) является функцией аргумента х. Нередко эта зависимость задается в табличном виде. В контрольных по математике на аппроксимацию также часто требуется найти некоторую аналитическую функцию, которая приближенно описывает заданную табличную зависимость. Кроме того, требуется определить значения функции в других точках, отличных от заданных табличных значений. Этой цели служит задача о приближении (аппроксимации). В этом случае находят некоторую функцию f(х), такую, чтобы отклонения ее от заданной табличной функции было наименьшим. Функция f(х) называется аппроксимирующей.
Вид аппроксимирующей функции существенным образом зависит от исходной табличной функции. В разных случаях функцию f(х) выбирают в виде экспоненциальной, логарифмической, степенной, синусоидальной и т.д. В каждом конкретном случае выбирают таким образом, чтобы достичь максимальной близости аппроксимирующей и табличной функций. Чаще всего, однако, функцию представляют в виде полинома по степеням х:
f(x) = ao + a1x + a2x2 + ... + anxn
Коэффициенты aj подбираются таким образом, чтобы достичь наименьшего отклонения полинома от заданной функции.
Таким образом, аппроксимация – замена одной функции другой, близкой к первой и достаточно просто вычисляемой".
Лично я редко пользуюсь полиномами в их классическом виде, как и другими стандартными представлениями, указанными в статье. Однако это уже нюансы технологии построения аппроксимирующих формул.
Еще раз – с пожеланиями успехов!
6.7.3. Технология решения задач аппроксимации функций средствами математических пакетов
6.7.3.1. Технология решения задач аппроксимации средствами MathCad
6.7.3.2. Технология решения задач аппроксимации функций в среде MatLab
6.7.4. Тестовые задания по теме «Аппроксимация функций»
Постановка задачи аппроксимации
Задача аппроксимации (приближения) функции заключается в замене некоторой функции y=f(x) другой функцией g(x, a 0 , a 1 , ..., a n) таким образом, чтобы отклонение
g(x, a0, a1, ..., an) от f(x) удовлетворяло в некоторой области (на множестве Х) определённому условию. Если множество Х дискретно (состоит из отдельных точек), то приближение называется точечным, если же Х есть отрезок , то приближение называется интегральным.
Если функция f(x)задана таблично, то аппроксимирующая функция
g(x, a 0 , a 1 , ..., a n) должна удовлетворять определённому критерию соответствия ее значений табличным данным.
Подбор эмпирических формул состоит из двух этапов – выбора вида формулы и определения содержащихся в ней коэффициентов.
Если неизвестен вид аппроксимирующей зависимости, то в качестве эмпирической формулы обычно выбирают один из известных видов функций: алгебраический многочлен, показательную, логарифмическую или другую функцию в зависимости от свойств аппроксимируемой функции. Поскольку аппроксимирующая функция, полученная эмпирическим путем, в ходе последующих исследований, как правило, подвергается преобразованиям, то стараются выбирать наиболее простую формулу, удовлетворяющую требованиям точности. Часто в качестве эмпирической формулы выбирают зависимость, описываемую алгебраическим многочленом невысокого порядка.
Наиболее распространен способ выбора функции в виде многочлена:
где φ(x,a 0 ,a 1 ,...,a n)=a 0 φ 0 (x)+a 1 φ 1 (x)+...+a m φ m (x), а
φ 0 (x), φ 1 (x), ..., φ m (x) – базисные функции (m-степень аппроксимирующего полинома).
Один из возможных базисов – степенной: φ 0 (x)=1, φ 1 (x)=х, ..., φ m (x)=х m .
Обычно степень аппроксимирующего полинома m<
e i = φ(x i , a 0 , a 1 , ..., a m) – y i , i = 0,1,2,...,n.
Методы определения коэффициентов выбранной эмпирической функции различаются критерием минимизации отклонений.
Метод наименьших квадратов
Одним из способов определения параметров эмпирической формулы является метод наименьших квадратов. В этом методе параметры a 0 , a 1 , ..., a n определяются из условия минимума суммы квадратов отклонений аппроксимирующей функции от табличных данных.
Вектор коэффициентов a T определяют из условия минимизации
![]()
где (n+1) – количество узловых точек.
Условие минимума функции Е приводит к системе линейных уравнений относительно параметров a 0 , a 1 , ..., a m . Эта система называется системой нормальных уравнений, её матрица – матрица Грама . Элементами матрицы Грама являются суммы скалярных произведений базисных функций
![]()
Для получения искомых значений параметров следует составить и решить систему (m+1) уравнения
![]()
Пусть в качестве аппроксимирующей функции выбрана линейная зависимость y= a 0 +a 1 x . Тогда
Условия минимума:
![]()
Тогда первое уравнение имеет вид
![]()
Раскрывая скобки и разделив на постоянный коэффициент, получим
![]() .
.
Первое уравнение принимает следующий окончательный вид:
![]() .
.
Для получения второго уравнения,приравняем нулю частную производную по а1:
![]() .
.
![]() .
.
Система линейных уравнений для нахождения коэффициентов многочлена ![]() (линейная аппроксимация):
(линейная аппроксимация):

Введем следующие обозначения  - средние значения исходных данных. Во введенных обозначениях решениями системы являются
- средние значения исходных данных. Во введенных обозначениях решениями системы являются
 .
.
В случае применения метода наименьших квадратов для определения коэффициентов аппроксимирующего многочлена второй степени y=a 0 +a 1 x+а 2 х 2 критерий минимизации имеет вид
![]() .
.
Из условия ![]() получим следующую систему уравнений:
получим следующую систему уравнений:

Решение этой системы уравнений относительно а 0 , а 1 , а 2 позволяет найти коэффициенты эмпирической формулы ![]() - аппроксимирующего многочлена 2-го порядка. При решении системы линейных уравнений могут быть применены численные методы.
- аппроксимирующего многочлена 2-го порядка. При решении системы линейных уравнений могут быть применены численные методы.
В случае степенного базиса (степень аппроксимирующего полинома равна m) матрица Грама системы нормальных уравнений G и столбец правых частей системы нормальных уравнений имеют вид
G
= 
В матричной форме система нормальных уравнений примет вид:
Решение системы нормальных уравнений
найдется из выражения
В качестве меры уклонения заданных значений функции y 0 , y 1 , ..., y n от многочлена степени m - φ(x)=a 0 φ 0 (x)+a 1 φ 1 (x)+...+a m φ m (x) ,
принимается величина

(n+1) – количество узлов, m – степень аппроксимирующего многочлена, n+1>=m.
На рис.6.7.2-1 приведена укрупненная схема алгоритма метода наименьших квадратов.
Рис. 6.7.2-1. Укрупненная схема алгоритма метода наименьших квадратов
Данная схема алгоритма метода наименьших квадратов является укрупненной и отражает основные процессы метода, где n+1 – количество точек, в которых известны значения х i , y i ; i=0,1,…, n.
Блок вычисления коэффициентов предполагает вычисление коэффициентов при неизвестных с 0 , с 1 , …, с m и свободных членов системы из m+1 линейных уравнений.
Следующий блок – блок решения системы уравнений – предполагает вычисление коэффициентов аппроксимирующей функции с 0 , с 1 , …, с m .

Пример 6.7.2-1. Аппроксимировать следующие данные многочленом второй степени, используя метод наименьших квадратов.
| x | 0.78 | 1.56 | 2.34 | 3.12 | 3.81 |
| y | 2.50 | 1.20 | 1.12 | 2.25 | 4.28 |
Запишем в следующую таблицу элементы матрицы Грамма и столбец свободных членов:
| i | x | x 2 | x 3 | x 4 | y | xy | x 2 y |
| 0.78 | 0.608 | 0.475 | 0.370 | 2.50 | 1.950 | 1.520 | |
| 1.56 | 2.434 | 3.796 | 5.922 | 1.20 | 1.872 | 2.920 | |
| 2.34 | 5.476 | 12.813 | 29.982 | 1.12 | 2.621 | 6.133 | |
| 3.12 | 9.734 | 30.371 | 94.759 | 2.25 | 7.020 | 21.902 | |
| 3.81 | 14.516 | 55.306 | 210.72 | 4.28 | 16.307 | 62.129 | |
| ∑ | 11.61 | 32.768 | 102.76 | 341.75 | 11.35 | 29.770 | 94.604 |
Система нормальных уравнений выглядит следующим образом

Решением этой системы являются:
а0 = 5.022; а1 =-4.014; а2=1.002.
Искомая аппроксимирующая функция
Сравним исходные значения yсо значениями аппроксимирующего многочлена, вычисленными в тех же точках:

Вычислим среднеквадратическое отклонение (невязку)
 .
.
Пример 6.7.3-1. Получить аппроксимирующие полиномы первой и второй степени методом наименьших квадратов для функции, заданной таблично.
 |
Пример 6.7.3-2. Осуществить аппроксимацию таблично заданной функции многочленом 1-й, 2-й и 3-й степени.
В этом примере рассмотрено использование функции linfit(x,y,f), где x,y- соответственно векторы значений аргументов и функции, а f – символьный вектор базисных функций. Использование этой функции позволяет определить вектор коэффициентов аппроксимации методом наименьших квадратов и далее невязку - среднеквадратическую погрешность приближения исходных точек к аппроксимирующей функции (сkо). Степень аппроксимирующего многочлена задается при описании символьного вектора f. В примере представлена аппроксимация таблично заданной функции многочленом 1-й, 2-й и 3-й степени. Вектор s представляет собой набор аппроксимирующих коэффициентов, что позволяет получить аппроксимирующую функцию в явном виде.
 |
В Mathcad имеется также большое количество встроенных функций, предназначенных для получения аналитического выражения функции регрессии. Однако в этом случае необходимо знать форму аналитического выражения. Ниже приведены встроенные функции, различающиеся видом регрессии, позволяющие (при заданных начальных приближениях) определить аналитическую зависимость функции, то есть возвращающие набор аппроксимирующих коэффициентов:
expfit(X,Y,g) Решение ОДУ 2-го порядка вида у”=F(x, y, z), где z=y’ также может быть получено методом Рунге-Кутты 4-го порядка. Ниже приведены формулы для решения ОДУ:
В этих функциях: х – вектор аргументов, элементы которого расположены в порядке возрастания; y – вектор значений функции; g – вектор начальных приближений коэффициентов a, b и с; t - значение аргумента, при котором определяется функция.
В приведенных ниже примерах для оценки связи между массивами данных и значениями аппроксимирующей функции подсчитывается коэффициент корреляции corr(). Если табличные данные неплохо аппроксимируется каким-либо видом регрессии, то коэффициент корреляции близок к единице. Чем меньше коэффициент, тем хуже связь между значениями этих функций.
Пример 6.7.3-3. Найти аппроксимирующие полиномы первой, второй, третьей и четвертой степени и вычислить коэффициенты корреляции.
| |
Помимо вычисления значений функций в пределах интервала данных все рассмотренные ранее функции могут осуществлять экстраполяцию (прогнозирование поведения функции за пределами интервала заданных точек) с помощью зависимости, основанной на анализе расположения нескольких исходных точек на границе интервала данных. В Mathcad имеется и специальная функция предсказания predict(Y, m, n), где Y – вектор заданных значений функции, обязательно взятых через равные интервалы аргумента, а m – число последовательных значений Y, на основании которых функция predict возвращает n значений Y.
Значений аргумента для данных не требуется, поскольку по определению функция действует на данных, идущих друг за другом с одинаковым шагом. Функция использует линейный алгоритм предсказания, который точен, когда экстраполируемая функция гладкая. Функция может быть полезна, когда требуется экстраполировать данные на небольшие расстояния. Вдали от исходных данных результат чаще всего оказывается неудовлетворительным.
Пример 6.7.3-4. Аппроксимировать функцию, заданную таблично, многочленом по МНК.
В этом примере рассмотрено использование функции p=polyfit(x,y,n), где x,y – соответственно векторы значений аргументов и функции, n – порядок аппроксимирующего полинома, а p – полученный в результате вектор коэффициентов аппроксимирующего полинома длинной n+1.
>> x=;
>> x
x =
1.2000 1.4000 1.6000 1.8000 2.0000
>> y=[-1.15,-0.506,0.236,0.88,1.256];
>> y
y =
-1.1500 -0.5060 0.2360 0.8800 1.2560
>> %
>> %
>> p1=polyfit(x,y,1);
>> p1
p1 =
3.0990 -4.8152
>> y1=polyval(p1,x);
>> y1
y1 =
-1.0964 -0.4766 0.1432 0.7630 1.3828
>> cko1=sqrt(1/5*sum((y-y1).^2));
>> cko1
cko1 =
0.0918
>> plot(x,y,"ko",x,y1,"r-")
 >> p2=polyfit(x,y,2);
>> p2
p2 =
-1.1321 6.7219 -7.6229
>> y2=polyval(p2,x);
>> y2
y2 =
-1.1870 -0.4313 0.2338 0.8083 1.2922
>> cko2=sqrt(1/5*sum((y-y2).^2));
>> cko2
cko2 =
0.0518
>> plot(x,y,"ko",x,y2,"r-")
>> p2=polyfit(x,y,2);
>> p2
p2 =
-1.1321 6.7219 -7.6229
>> y2=polyval(p2,x);
>> y2
y2 =
-1.1870 -0.4313 0.2338 0.8083 1.2922
>> cko2=sqrt(1/5*sum((y-y2).^2));
>> cko2
cko2 =
0.0518
>> plot(x,y,"ko",x,y2,"r-")
 |
Пример 6.7.3-5. Аппроксимировать функцию, заданную таблично, многочленом по МНК.
 |
Пример 6.7.3-5. Аппроксимировать функцию, заданную таблично, полиномами различной степени по МНК.
6.7.4. Тестовые задания по теме
«Аппроксимация функций»
Аппроксимация – это
1) получение функции более простого вида, описывающей исходную с достаточной степенью точности
2) частный случай интерполяции
3) замена исходной функции функцией другого вида
4) в списке нет правильного ответа
Тема 6.7. Аппроксимация функций
6.7.1. Постановка задачи аппроксимации
6.7.2. Метод наименьших квадратов